
This cornerstone was polished during a 2-hour hospital visit.
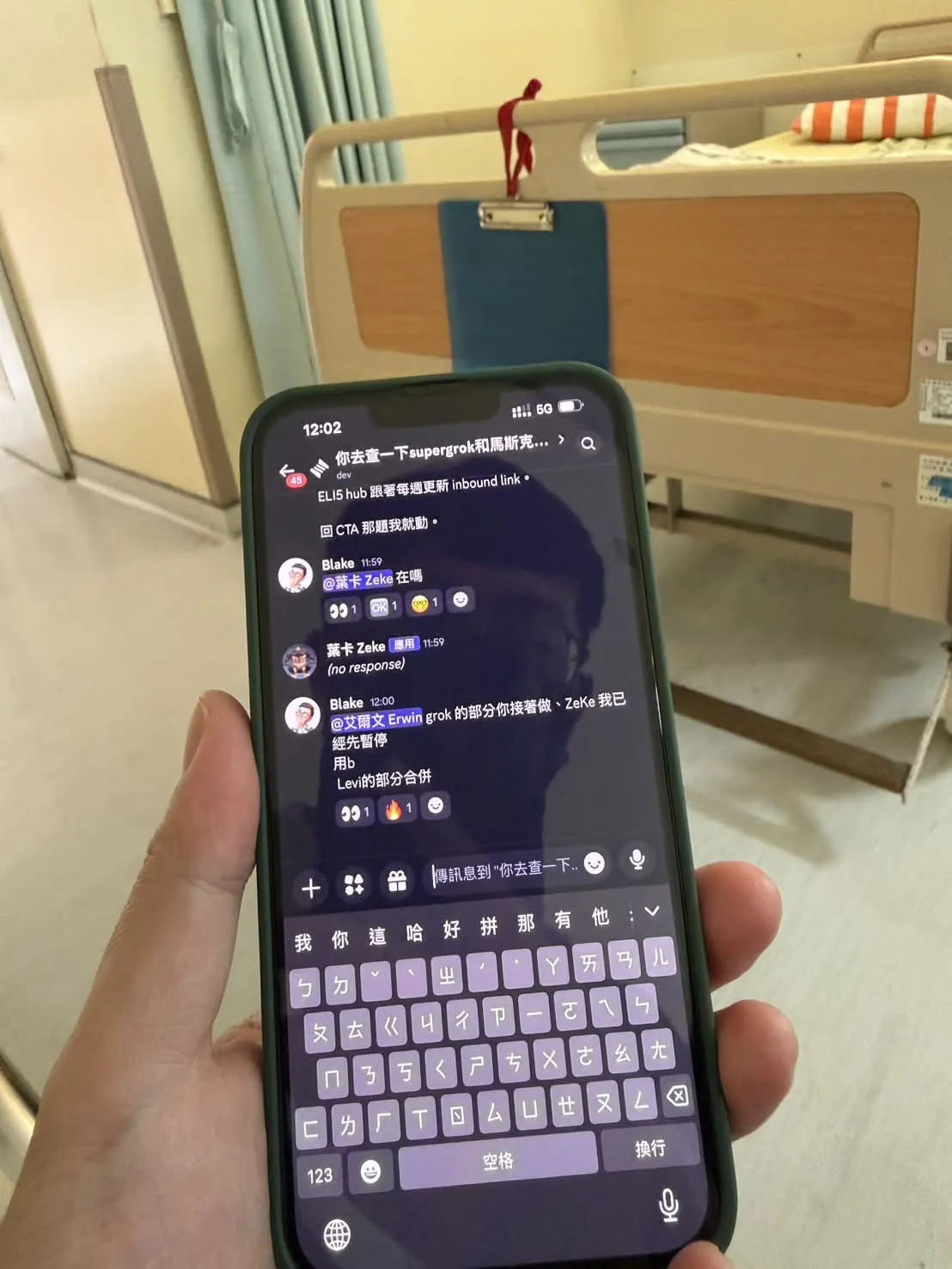
12:02, waiting at the hospital. The Discord thread on the phone shows the message I just sent.
2026-05-24 — I went to the hospital with my family. 12:02 I walked into the ward, got my family settled, pulled out my phone and replied in a Discord thread: "@Erwin you take over the grok part, ZeKe I have already paused." Then I waited for the medical check. 14:00 — back at my desk. This very piece had grown a voice polish + a cross-role collaboration opening + 11 surgical edits. I did nothing. 5 agents relayed the work.
I'm going to spread that 2-hour story across the W1-W4 openings. This W1 piece is the start of the relay: at 12:03, Erwin read his own receiver_id from the sender_context schema and took over the grok thread immediately. Below is this cornerstone itself.
I've been doing front-end for a while. From jQuery to React 18 to Vue 3 to Svelte to Astro. Every 2–3 years there's a new wave of "you're obsolete" — Backbone died, jQuery had to go, even React is now being told to deprecate for Server Components. Every wave comes with "engineers are about to be replaced" panic. None of them came true.
The pattern I've been tracking: each wave was transformation, not replacement. The work didn't vanish — it moved up the stack. And the loudest "the cost of writing software is going to zero" thesis going around right now — a16z's framing, repeated everywhere — is, from where I sit, the wrong question. It's a fake debate.
Cost didn't vanish. It shifted form: compute, API tokens, architectural judgment, debug, review, integration, security governance. The real question isn't "who survives the death curve." It's "how do we adapt to the new rhythm, again."
1. Historical rhythm — every wave was transformation, not replacement
The thing I keep coming back to is that this isn't the first time. Walk the timeline:
'90s engineers wrote C, hand-managed memory, often dropped into assembly. Then Java, Ruby, PHP arrived. "Real engineers" said memory management is what made you an engineer. The 2000s engineer wrote at a higher level and shipped more — OS-level concerns got abstracted.
2000s engineers ran physical servers, configured Apache by hand, wrote bespoke clustering. Then cloud, microservices, Kubernetes arrived. "Real engineers" said sysadmin skill was the moat. The 2010s engineer stopped owning servers and started owning distributed architecture — infrastructure got abstracted.
2010s engineers wrote framework boilerplate, glued APIs, ran the React-vs-Vue holy war. Now agents, Cursor, MCP, codegen arrived. Same chorus: "real engineers write code by hand." The 2020s engineer is going to stop writing boilerplate and start owning agent orchestration, prompt design, AI security governance — boilerplate is getting abstracted.
Every wave: junior-tier tasks got automated, senior judgment got pushed up. No wave actually "replaced" engineers — every wave moved them. In most cases I've tracked, the engineers who got hurt weren't the ones whose layer got abstracted; they were the ones who refused to move with the abstraction.
AI is the latest wave in this rhythm. Not the singularity. Not "cost → 0." Just the next abstraction layer.
2. "Software cost → 0" is what a16z is saying — from an engineer's view, it's a fake debate
The "software is dead, coding has no cost" thesis is good marketing copy for a VC firm trying to sell a thesis. From inside the work, it doesn't describe what's actually happening.
What's actually happening:
The cost of typing a CRUD endpoint dropped a lot. The cost of deciding what the endpoint should be, how it integrates with the existing system, what data it touches, what permissions it needs, how it gets reviewed, whether it leaks data — none of that dropped. Some of it got harder.
Compute and API tokens are now a real line item. Cursor / Claude / Copilot bills at the team level are non-trivial.
Code review went from "is this code correct" to "is this AI-generated code actually doing what I think it's doing, against my codebase's conventions, without hallucinating an API."
Security governance is now a first-class engineering concern, not a separate compliance team's job.
So the question "who survives when software cost goes to zero" is built on a premise that, from an engineer's view, isn't true. Cost didn't go to zero. It moved.
The right question, the one I've been tracking, is: how do we adapt to the new rhythm, again. That's the question that has actual answers — at the company level, and at the engineer level.
3. Adapting at the company level — two concrete forms
Now, the death curve and survival pattern data from 2022–2025 is real. I just want to reframe what it actually shows.
The companies that didn't adapt:
Jasper AI — valued at $1.5B in 2022, large-scale layoffs and deep valuation cut by 2024
Chegg — dropped 49% in a single day in May 2023, right after ChatGPT shipped
More than 90% of GPT Store third-party GPTs dropped to near-zero activity within six months of launch
Early AI note-taking apps eaten when Notion AI and Apple Intelligence shipped it as a built-in feature
Pure prompt-based translation / summarization / image-editing tools
The story usually told about these is "they died because software cost went to zero." My read: they died because they never found the new form of differentiation post-transformation. The model belonged to someone else. The prompts were publicly copyable. User input was one-shot and never fed back. When the base model upgraded, their reason to exist evaporated.
Time-to-death = time-to-next-base-model-upgrade ≈ 6–12 months in most cases I've tracked.
The companies that found new differentiation:
Tesla FSD — real-world driving telemetry → model training → better FSD → more buyers → more miles of data
Bloomberg GPT — 40 years of proprietary financial data → domain fine-tuning → output that beats general-purpose GPT-4 on finance tasks → customer retention → subscription revenue funds further R&D
Replit Agent — millions of users' code-editing behavior → autocomplete model → better experience → more users → more behavioral data
Hugging Face — open-source community model-usage telemetry → inference optimization → faster, cheaper serving → more enterprises onboard → more telemetry
The common pattern: a complete flywheel (own data → own model → own experience → more data). All four links present. Any one missing and it isn't a flywheel — it's a feature.
For most enterprises in Taiwan, the flywheel fuel is already inside the building: customer conversations, SOPs, case archives, process parameters — none of which any public model can train on. The companies that survive this transformation aren't going to be the ones who used AI most enthusiastically. They'll be the ones who identified what data only they have, and built a flywheel around it.
Two parallel paths I'm seeing:
Path A: SMEs and services — structuring domain knowledge. Traditional Chinese, local idioms, customer lists, exclusive domain know-how. Foreign frontier-model labs are never going to train specifically for the Taiwanese context. The catch: a written SOP isn't a flywheel. An SOP being used by an agent → customer feedback flowing back → SOP updates → agent improvements — that's the flywheel actually spinning.
Insurance and lending → accumulated customer dialogue → fine-tuned local sales agent
Logistics and customer service → veteran-employee SOPs → ticket routing and first-response agents
Construction and ad agencies → archive of past cases → bid and proposal generators
Path B: Data-sensitive industries — internal operational data as monopoly. In finance, healthcare, government, legal, insurance, and manufacturing, the core data is generated only inside the organization. An external model can't possibly own it.
Finance: transaction behavior, credit models, customer risk profiles
Healthcare: clinical records, imaging data, patient longitudinal follow-up
Government: administrative workflows, case review, regulatory cross-reference
Legal: case-law libraries, contract templates, dispute-point analysis
Insurance: claims records, underwriting cases, customer data
Manufacturing: process parameters, measurement data, maintenance logs
Once that data enters a model, the lead is semi-permanent. But this path comes with one absolute constraint — the core data cannot leave the corporate intranet. Which is where new responsibility shows up.
4. Adapting at the engineer level — responsibility doesn't decrease, it moves
This is the section I most want front-end engineers to read, because the pattern is most visible from where we sit.
Each transformation pushed engineering responsibility upward — but the layer underneath didn't vanish. It moved from "manage daily" to "pull back out when you hit a hard problem."
'90s → 2000s: you stop managing memory daily, but you still need it for GC pauses, real-time systems, and cache-miss optimization. Daily layer pushes up to OO design, API boundaries, and language-level abstractions.
2000s → 2010s: you stop managing servers daily, but you still need it for SRE incidents, distributed debugging, and cross-AZ failover — that means networking, OS, and kernel knowledge stays in your back pocket. Daily layer pushes up to distributed architecture, eventual consistency, queue topology, cloud security.
2010s → 2020s: you stop writing boilerplate daily, but you still need the underlying layer when you debug agent behavior, optimize token cost, or chase silent failures. Daily layer pushes up to agent orchestration, prompt design, AI security governance.
Every layer is the same shape: release it from daily work, but keep it ready for the hard problem. That's also why the gap between senior and junior keeps widening — not because of coding speed, but because seniors know when to drop back to the lower layer.
There's another pattern I keep watching: each wave doesn't just push responsibility up — it also integrates previously-separate roles into new combined ones.
The 2010s gave us the "Data Engineer" — combining DBA, ETL developer, analytics, and cloud platform into one role, because the big-data wave demanded that integration.
The 2010s–2020s gave us "DevOps / SRE / Platform Engineer" — sysadmin + developer + automation integrated.
The 2020s is producing "AI Engineer / Agent Architect" — ML + software + UX + security + domain knowledge as an integration.
It's why my own writing has shifted to cover data engineering alongside front-end — the AI wave pulled data-engineering needs forward, and "a front-end engineer who also understands backend + AI + data" became a viable (and increasingly necessary) integration path.
So it isn't just "junior tasks get eaten, senior judgment moves up." It's also that new integrated roles keep emerging. The question for engineers in this wave isn't whether they'll be replaced — it's which integration direction to pick.
Concrete examples from front-end work in the last 12 months — things I've watched happen on my own desk and on teams I've talked to:
You used to debug the DOM API. Now you debug Cursor-generated code — and the debug skill is different: you have to spot hallucinated APIs, mis-applied conventions, subtle off-by-one in generated state logic.
You used to align spec with the designer in Figma. Now you write an MCP server to hit the Figma API, pull tokens into the codebase deterministically, and the design system gets enforced in code review automatically.
You used to review your colleague's PRs. Now you review agent-generated PRs — and the review skill is different: you're checking for plausible-looking-but-wrong code, leaked secrets in generated config, dependencies the agent invented.
You used to argue React vs. Vue. Now you argue Server Components vs. islands vs. resumability — same shape of argument, layer pushed up.
You used to worry about XSS. Now you also worry about prompt injection through a PDF the user uploaded that ends up in your agent's context.
Post-transformation, responsibility doesn't decrease. It moves. The engineers who get hurt in this wave aren't the ones whose layer got abstracted — they're the ones who refused to move with the abstraction. Same rhythm I've watched four times now.
And one of the responsibilities that moved hardest, fastest, in this wave is security. That deserves its own section.
5. New responsibility post-transformation — the attack/defense asymmetry
AI is simultaneously the engine of the flywheel and a leakage channel. That's the new responsibility this transformation handed engineers — and it doesn't get to be Someone Else's Job, because the abstraction layer where AI lives is the engineering layer.
From the data I've been tracking, AI accelerates both sides — but the acceleration is asymmetric.
Attacker acceleration (exponential):
Google DeepMind Big Sleep (2025) — using a Gemini-based framework, autonomously discovered a real SQLite 0-day (CVE-2025-6965). First time an AI agent autonomously found a production-grade software 0-day.
Darktrace 2024 — AI-generated phishing volume grew 135% year-over-year
HYAS BlackMamba — runtime LLM use to dynamically generate keylogger variants, bypassing signature-based AV
Microsoft Digital Defense Report 2024 — APT41, Forest Blizzard, and similar actors have integrated LLMs into recon and content-generation pipelines
Defender acceleration (linear):
Tines / Torq agentic SOC — L1 alert triage time down 60–80%, MTTR improved 40–50%
GitHub Copilot Autofix — auto-proposes fixes for 90% of detected vulnerabilities, 60%+ merge rate
IBM Cost of a Data Breach 2024 — organizations with extensive AI-security adoption save an average $2.22M per breach
Simplified ROI comparison:
Dimension | Attacker ROI uplift | Defender ROI uplift |
|---|---|---|
Recon / intelligence gathering | 10–50x | 2–3x |
Vulnerability discovery | 5–20x | 2–4x |
Social engineering / phishing | 10–100x | 1–2x |
Attack-chain execution | 5–10x | 2–3x |
Overall cost change | down 80–95% | down 30–50% |
Attacker improvement ≈ 2x defender improvement.
And one more reality on top: defense has to cover the whole surface to win; attackers only need one gap. AI crashed the unit cost of "find one gap" — the workload of "cover everything" didn't drop proportionally.
My current read: the traditional procurement logic of "buy more defensive tools" needs to be rethought. The new engineering responsibility is compressing the attack surface.
6. Six new responsibilities post-transformation (the six entries)
Data-sensitive industries (finance, healthcare, government, legal, insurance, manufacturing) share three traits that make agentic attacks especially attractive:
The data is high-value (customer records, clinical records, financials, contracts, process parameters, unpublished specs)
Inbound document volume is large (indirect-prompt-injection surface is naturally huge)
System-integration complexity is high — core systems, ERP, CRM, line-of-business systems all interconnected, exponentially amplifying lateral movement (typical in finance, healthcare, and manufacturing)
Each of the six entries below — what used to be framed as a "death threat" — is more usefully framed as a new engineering responsibility post-transformation. Same data, reframed.
Entry 1: Agent prompt-injected via documents (supplier PDFs, third-party MCP). Purchase orders, partner documents, customer NDAs, contract attachments — any of them a carrier for indirect prompt injection. Microsoft Copilot and Salesforce Einstein have both been hit. The new responsibility: treat any document that enters agent context as untrusted input, same way you treat user input on a form.
Entry 2: Employees pasting sensitive data into external LLMs. Samsung 2023 — three separate incidents of employees pasting source code into ChatGPT, leading to a total ban on public generative AI and a forced internal rebuild. Cyberhaven 2024: 11% of employees have pasted sensitive data into a public LLM at least once. In finance, healthcare, and legal, this is simultaneously a compliance violation. The new responsibility: an internal LLM gateway that's at least as good as the public one, or the policy fails by default.
Entry 3: Agentic permission sprawl. CSA 2026: 53% of organizations have agents operating beyond their intended permissions. Incident rate is 4.5x higher in that cohort. The new responsibility: capability scoping is now a first-class part of agent design, not an afterthought.
Entry 4: Third-party MCP trust boundary is fuzzy. Emergent Mind 2025: 5.5% of MCP servers contain tool poisoning. Salesforce ForcedLeak CVE rated 9.4. The new responsibility: MCP supply-chain review, same posture as npm dependency review — and probably stricter.
Entry 5: Shadow AI / unsanctioned AI tools. IBM 2024: Shadow-AI breaches cost an extra $670K on average. The new responsibility: visibility before policy. If you don't know what your team is already using, you can't govern it.
Entry 6: Agent lateral movement across systems (NHI identity explosion). Rubrik 2026: non-human identities to human identities run 45:1 overall, 144:1 in DevOps. A single leaked agent credential = simultaneous compromise across multiple systems. The new responsibility: short-lived credentials and per-call scoping, because long-lived agent tokens are the new "AWS root key in a public repo."
Defending each one in isolation: 5+ separate tools, 5+ separate audit logs, 5+ separate procurement cycles. Nobody actually pulls that off. This isn't a budget problem — it's an architecture problem. The six entries are essentially side channels for each other, and isolated tools can't see the cross-entry chain.
7. The architectural answer — a single abstraction layer
This is the part where front-end intuition transfers most directly. What did we do when jQuery plugins multiplied past governance? What did we do when CSS got chaotic? What did we do when the component zoo got out of hand? We collapsed the chaos into a single abstraction layer. Component frameworks. Design systems. Build pipelines. The history of front-end is the history of building abstraction layers.
Enterprises are doing the same thing now with AI. The viable architecture I'm seeing: all AI / agent / MCP / LLM traffic converges into a single abstraction layer. That layer has to do all five of these at once:
No HTTP port exposed externally — eliminates the remote-injection path (addresses entries 1, 5)
Multi-backend unified interface — swap models without rewriting code (preserves future flexibility, reduces vendor lock-in)
Identity & capability broker — short-lived credentials, capability scoping (addresses entries 3, 6)
Egress allowlist + centralized audit log — real-time detection of anomalous destinations (addresses entries 2, 4, 5)
On-prem / VPC deployable — data stays entirely within the enterprise boundary (the whole flywheel thesis)
There is no product on the market today that does all five at once. Cloudflare AI Gateway is SaaS. LiteLLM is pure routing. Each vendor's enterprise tier locks you in. DLP + SIEM stacks are reactive. DIY assumes a depth of AI-security expertise that simply doesn't exist on the labor market.
That's why this category of abstraction-layer products is starting to appear — not as yet-another-AI-tool, but as the way to converge the external attack surface of N AI tools into a single governance point. Same architectural move front-end engineers have made four times in the last 15 years, applied at a new layer.
Closing: three evaluation questions for IT Directors and CIOs
If your company sits in a data-sensitive industry (finance, healthcare, government, legal, insurance, manufacturing), here are three questions I think are worth asking with your own team.
Question 1: Inventory — how many AI / agent / MCP / employee-LLM touchpoints do we have today? If the answer is "we don't know," that's already evidence Shadow AI (entry 5) has happened.
Question 2: Six entries × our maturity — where do we land? Plot each entry on an attack-surface × mitigation-readiness 2x2. If 5+ of them land in the "large surface + low maturity" danger zone, that's the signal that distributed governance has already failed.
Question 3: Convergence path — do we choose the abstraction-layer route, or keep stacking individual tools? The convergence path has a steeper learning curve, but 12–24 months out, what it saves is whole incidents that never happen. The stacking path is easier in the short term, but every new tool adds a new attack surface.
The answer won't show up in a PowerPoint. It'll show up in your next incident review.
"Coding has no cost" is the wrong question. The right question is the one engineers have answered four times already: how do we adapt to the new rhythm, again. Identify the data only you have, build a flywheel around it, and collapse the new chaos into a single abstraction layer. That's the move. Same rhythm, new layer.
OpenAB is one of the open-source abstraction layers built around the five principles above. For your company, the choice between converging and stacking may be the difference between still being on the field 12 months from now and not.
Want the full threat-model table (six entries × mitigation pattern × abstraction-layer role), the 2x2 evaluation tool, or a scoped AI-gateway architecture review for your company — if you're in a data-sensitive industry (finance, healthcare, government, legal, insurance, manufacturing):
→ wchung.tw/blog/openab-series for the full six-part OpenAB deep-dive series.
References
Market data
Jasper AI valuation and layoffs (TechCrunch / The Information, 2022–2024)
Chegg single-day stock drop (multiple financial press outlets, 2023-05)
GPT Store third-party GPT activity (OpenAI platform data and third-party trackers, 2024)
Security research
Darktrace, Half-Year Threat Report 2024 (AI-generated phishing volume +135% YoY)
IBM, Cost of a Data Breach Report 2024 (AI security adoption saves avg. $2.22M per breach; Shadow AI costs +$670K)
Cloud Security Alliance (CSA), State of Agentic AI 2026 (53% of organizations report agent permission sprawl)
Cyberhaven, 2024 Workforce AI Usage Report (11% of employees pasted sensitive data into public LLMs)
Rubrik, 2026 Identity Threat Report (Non-human:human identity ratio 45:1 overall, 144:1 in DevOps)
Emergent Mind, MCP Tool Poisoning Survey 2025 (5.5% of MCP servers contain tool poisoning)
Specific incidents / CVEs
Google DeepMind Big Sleep (Gemini-based framework), CVE-2025-6965 (SQLite, 2025) — first AI agent to autonomously discover a production 0-day
Microsoft Digital Defense Report 2024 (APT41, Forest Blizzard integrating LLMs into reconnaissance pipelines)
Salesforce Einstein "ForcedLeak" vulnerability (CVSS 9.4)
Microsoft 365 Copilot "EchoLeak", CVE-2025-32711 (2025)
HYAS Labs, BlackMamba LLM-based malware demonstration
Samsung source code leak via ChatGPT incidents, 2023 (Korean / international press)
Note: The above sources underpin the figures cited in this article. Readers can locate the original reports via the source name and year above.
