聲明: 本專案為個人學習用途的 side project。所有數據皆為程式產生的 synthetic data,不包含任何真實患者資料。架構設計參考公開的醫療數據工程實務,不代表任何特定公司的內部實作。
背景:我的 mentor 說了一句話
「工程師不能只跑數字,要能解釋數字。」
這是我 mentor 給我的第一課。他不讓我碰 Dagster UI,也不讓我花時間在 Airflow 上。他說:「工具會換,但你對資料的理解不會。」
問題是 — 我是前端出身,看到 Polars 的 group_by().agg() 像在讀天書。Pipeline 跑完吐出一堆數字,我知道它跑了,但不知道它做了什麼。
所以我決定用我擅長的方式來學:寫一個 Dashboard。

我的 Pipeline 長什麼樣
先講一下我在拆解的東西。我根據公開的醫療數據工程實務,自己設計了一條 CGM(連續血糖監測)數據 Pipeline,用程式產生 500 位虛擬患者 90 天的 synthetic 血糖數據。
Generator → Ingestion → Quality (補值) → Analytics
500 users 4 assets 1 asset 3 assets
966K CGM 分區寫入 補值到 1.08M 聚合成報告
8 個 Dagster Asset、3 層架構、16.5 秒跑完。聽起來不大,但裡面藏了很多值得挖的東西。
Page 1: Raw Data — 第一個發現:資料本來就有缺
我以為 Generator 會給我完美的資料,但打開一看:
指標 | 理論值 | 實際值 | 差異 |
|---|---|---|---|
CGM Readings | 1,080,000 | 966,799 | -10.5% |
少了 11 萬筆。
原因是我在 Data Generator 中刻意模擬了 CGM 感測器的真實世界問題 — 感測器會斷訊、會脫落、會沒電。每個 user 有 2-5 次 gap event,加上 5-15% 的隨機 drop。這些模擬規則參考了公開的 CGM 臨床文獻。
這是我學到的第一件事:真實世界的資料從來不是完整的。Pipeline 的 Quality 層存在的意義,就是處理這些「不完美」。
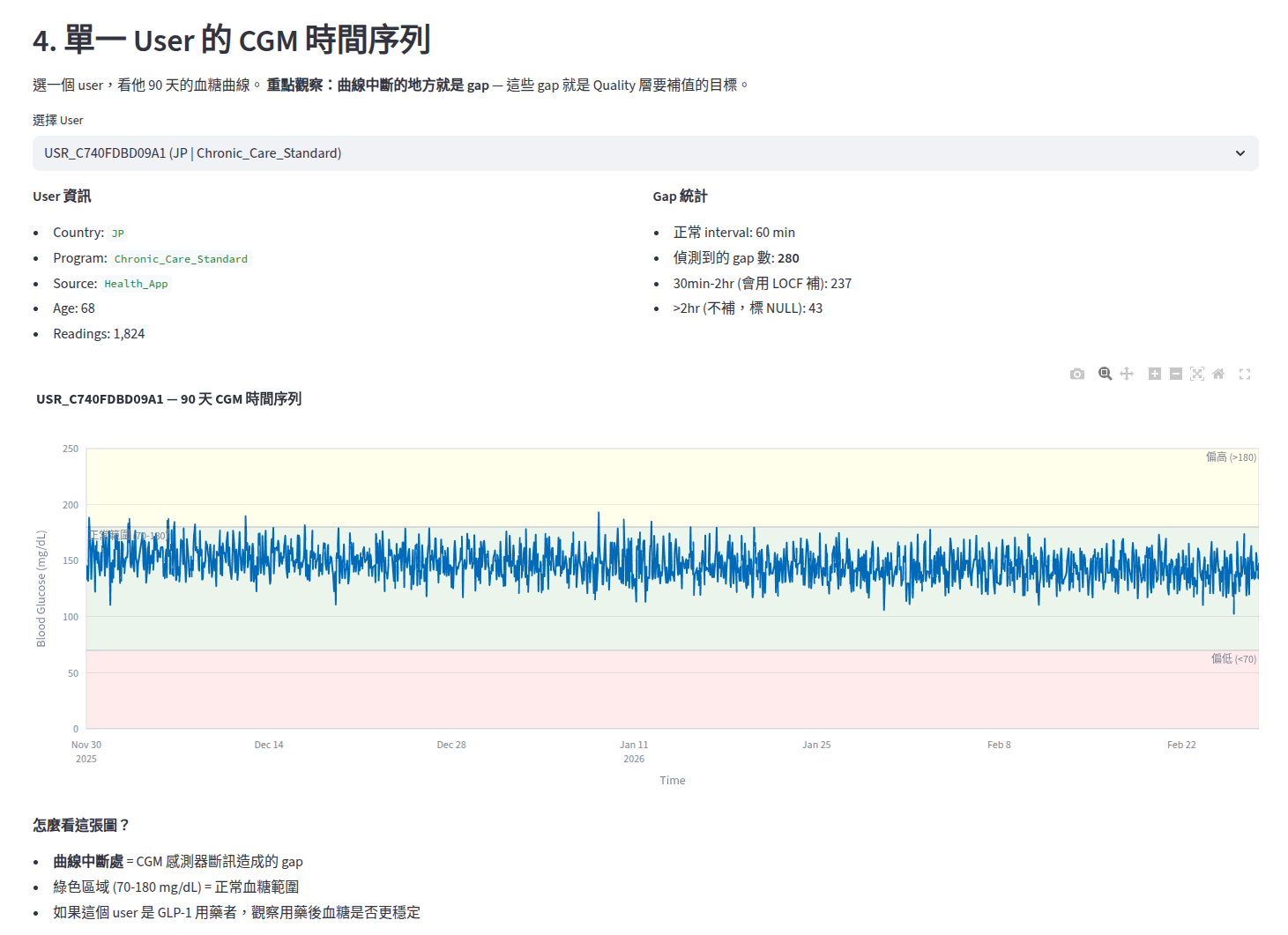
當我選了一個 user 畫出他 90 天的血糖曲線,那些斷掉的線段就是 gap — 非常直觀。
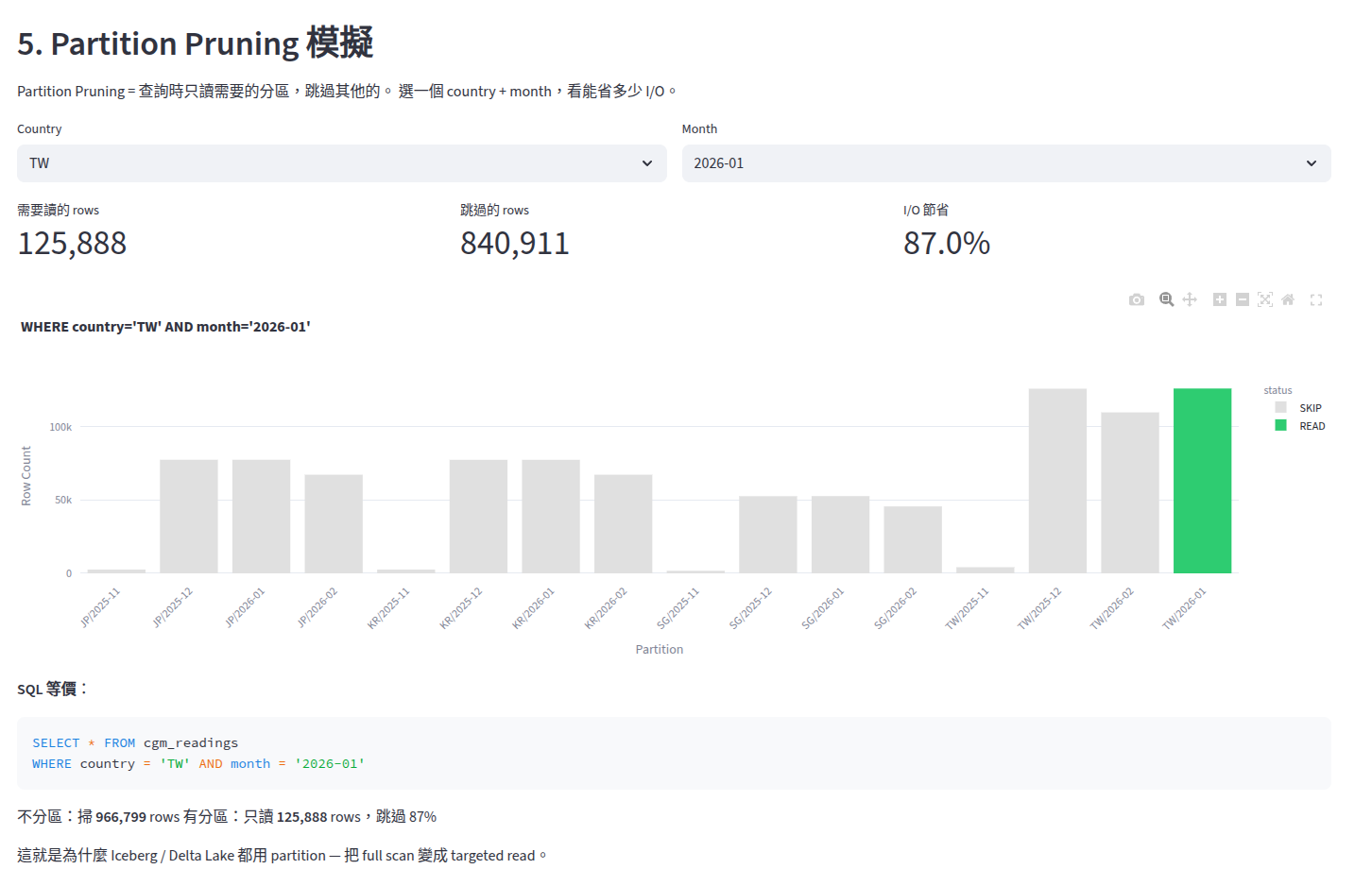
Page 2: Partitioning — 第二個發現:35.6 倍的 Skew 是假的
Ingestion 層做的事很簡單:把一個大檔拆成按 country × month 分區的小檔。
data/iceberg/cgm_readings/
├── country=TW/month=2026-01/data.parquet (60K rows)
├── country=TW/month=2025-11/data.parquet (4K rows)
├── country=SG/month=2025-11/data.parquet (1.7K rows)
└── ...(共 16 個 partition)
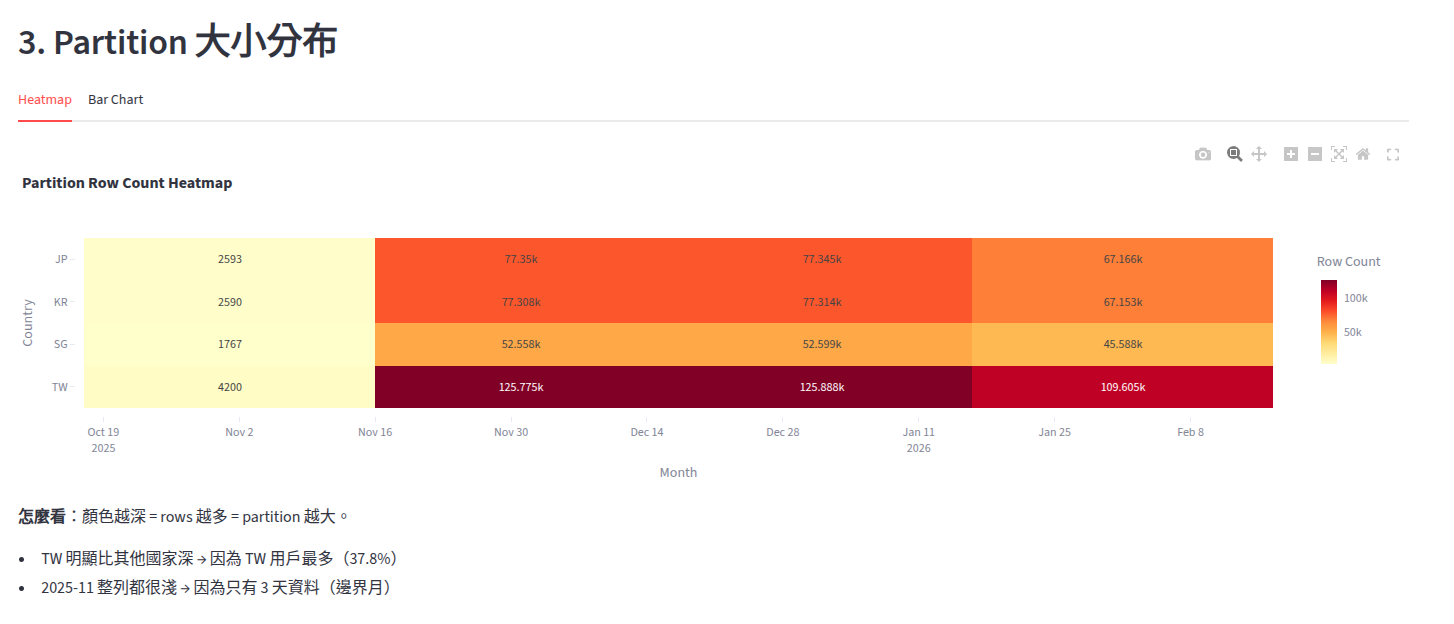
Dashboard 上的 Heatmap 一打開,我就看到一個嚇人的數字:Data Skew = 35.6x。最大的 partition 是最小的 35.6 倍。
但我學到不能只看數字。拆開分析:
2025-11 只有 3 天資料(邊界月),所以那些 partition 本來就小
排除邊界月後,真實 skew 只有 2.9x — 反映 TW 37.8% vs SG 15.8% 的用戶分布
這是 mentor 說的「解釋數字」。如果有人問你 skew 多少,你不能只說 35.6x,要能拆出「邊界效應」和「業務現實」兩個因素。
我還做了 Partition Pruning 模擬器 — 選一個 country + month,Dashboard 會即時算出跳過了多少 I/O。查 TW 的 2026-01 只需要讀 6% 的資料,省了 93% I/O。
Page 3: Imputation — 第三個發現:最重要的一頁
這是整個 Dashboard 最核心的頁面。Quality 層對 CGM 的 gap 做醫療級補值,規則來自 FDA CGM Guidance + ATTD Consensus:
Gap ≤ 30 min → Linear Interpolation(血糖短期近似線性)
Gap 30min-2hr → LOCF(前值遞補,保守策略)
Gap > 2hr → NULL(不補,避免 survivorship bias)
Dashboard 上的 Pie Chart 顯示了一個反直覺的結果:Linear Interpolation = 0。
為什麼?因為 Demo 的 interval 是 60 分鐘(每小時一筆),所以最小的 gap = 120 分鐘,已經超過 30 分鐘門檻。Production 用 5 分鐘 interval 時,短 gap 才會觸發 Linear Interpolation。
最直觀的視覺化是單一 User 的補值前後對比:
藍色線 = 原始讀數
紅色 × = LOCF 補值(出現在藍色線斷掉的地方)
灰色 △ = NULL(gap 太大,不補)
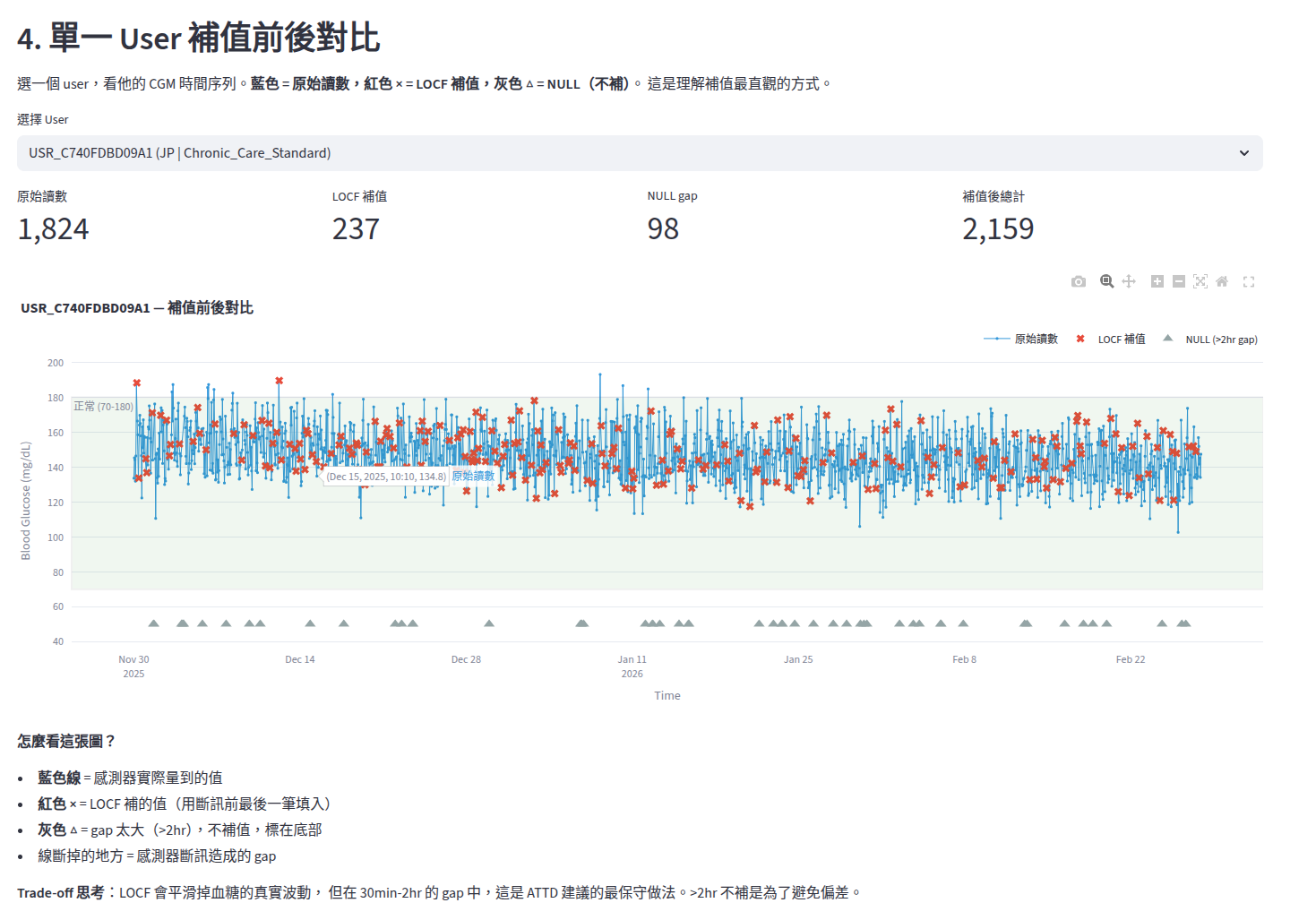
看到這張圖的瞬間,我才真正理解「Last Observation Carried Forward」是什麼意思 — 它就是把斷訊前的最後一個值,直接複製到 gap 裡面。
Page 4: Analytics — 第四個發現:百萬行壓成 90 行
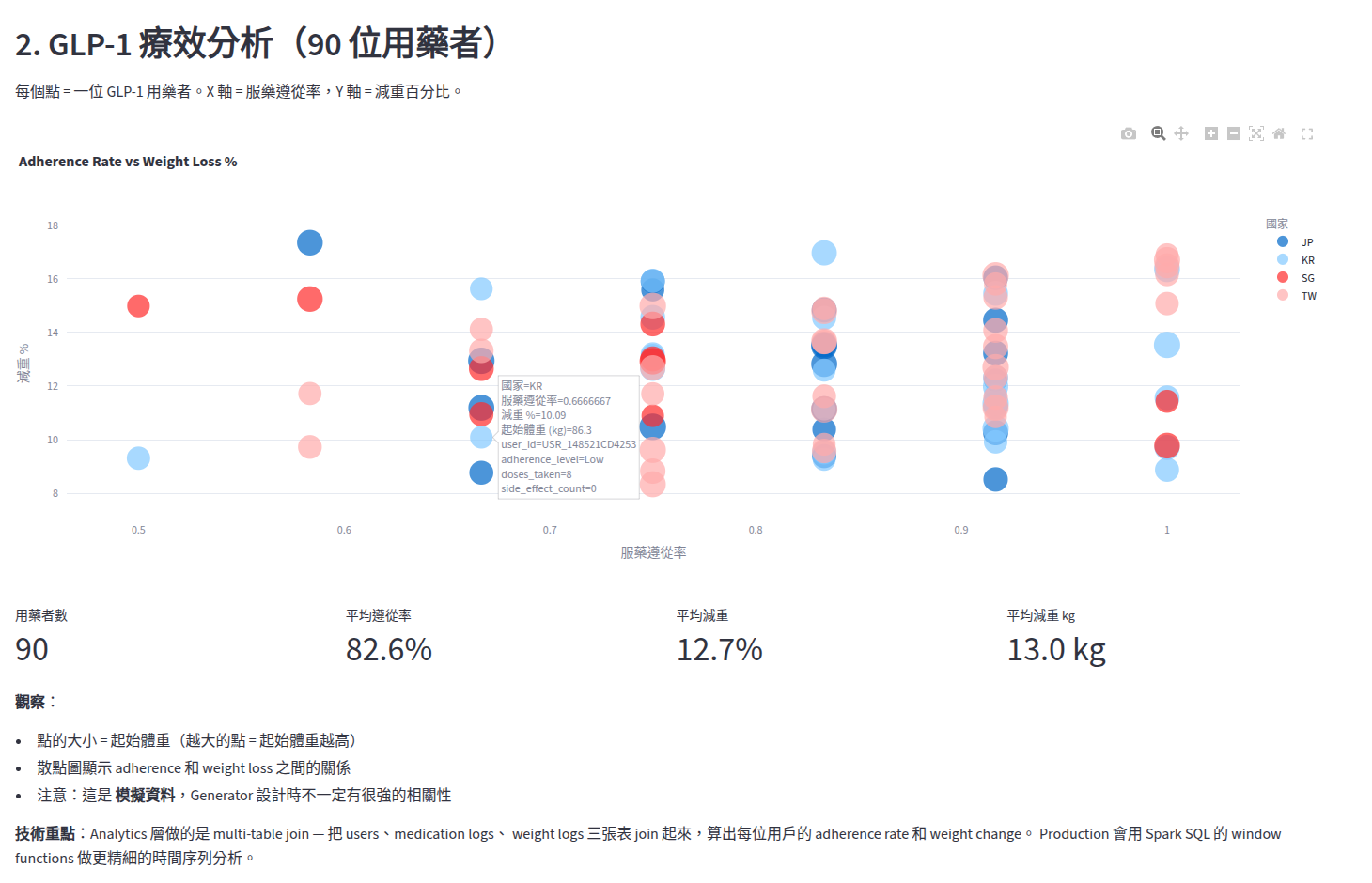
Analytics 層做的是 multi-table join — 把 users(500)、glp1_logs(1,080)、weight_logs(6,000)三張表 JOIN 起來,算出每位 GLP-1 用藥者的療效。
輸出只有 90 行(因為只有 90 位 GLP-1 用戶)。從百萬級壓到兩位數,這就是聚合的力量。
Dashboard 上的散點圖讓我看到 adherence rate 和 weight loss 的關係,雖然模擬資料的相關性不強,但 join 邏輯是對的 — 這才是 POC 的價值。
藥物比較也很有趣:模擬數據中 Mounjaro 的副作用率 21.4% 最低,Adherence 也最高。當然這是 synthetic data 的結果,真實世界的藥物比較需要 RCT(隨機對照試驗)才有臨床意義。
Page 5: Pipeline Overview — 第五個發現:一個 Asset 吃掉九成時間
最後一頁把所有認知串在一起。
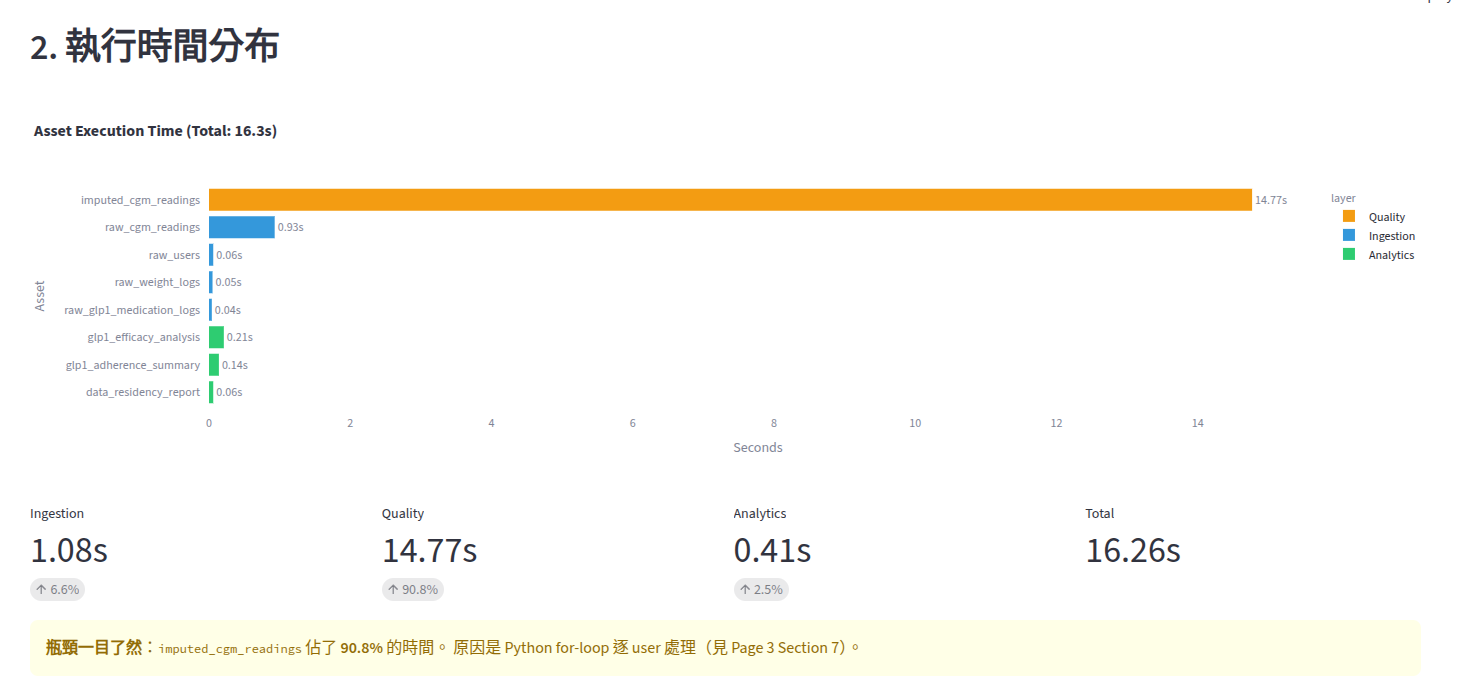
時間瀑布圖上,imputed_cgm_readings 像一根巨大的橫條,佔了 89.8% 的時間。其他 7 個 Asset 加起來只佔 10%。
層 | 時間 | 佔比 |
|---|---|---|
Ingestion (4 assets) | 1.08s | 6.6% |
Quality (1 asset) | 14.77s | 89.8% |
Analytics (3 assets) | 0.41s | 2.5% |
原因是 Python for-loop — 逐 user 處理 500 個用戶,每次都要把 Polars DataFrame 序列化成 Python dict,再逐行產生補值結果。用 Python 的方式操作了一個 Rust 引擎的工具。
Sankey 資料流量圖讓我看到另一個視角 — CGM 的 966K rows 是絕對大宗,其他表都是千位數以下。Pipeline 的「胖瘦」一目了然。

規模推算表告訴我:100K users 時 imputation 會跑 ~49 分鐘。不優化就上 Production 是不行的。
優化路線:
短期:Python for-loop → Polars
group_by().map_groups()— 預估 5-10x 提升中期:Eager → Lazy API — 再 2-3x
長期:上 Spark — 水平擴展
我學到了什麼
Dashboard 教會我的
回到 mentor 的那句話:「工程師不能只跑數字,要能解釋數字。」
5 頁 Dashboard 下來,我可以回答:
Pipeline 有幾個 Asset?各層做什麼?(8 個,3 層)
瓶頸在哪?為什麼?(imputation 90%,Python for-loop)
Data Skew 多少?怎麼解讀?(35.6x 是假象,排除邊界月後 2.9x)
補值規則是什麼?為什麼 Linear = 0?(interval 60min > 30min 門檻)
Production 怎麼 scale?(Polars lazy → Spark)
Dashboard 沒教會我的
但我也很誠實地面對一件事:我還不會用程式碼操作這些資料。
我看得懂散點圖上每個點的意義,但寫不出 pl.col("adherence_rate").mean().over("country")。我知道 Partition Pruning 省了 93% I/O,但說不清楚 Parquet 的 column pruning 為什麼比 CSV row scan 快。
Dashboard 讓我有了「資料直覺」— 我知道每行 code 應該產出什麼結果。接下來的 Module 1-3,我要帶著這份直覺去真正寫 code、做優化、拆成本。
給同樣在轉職的人
如果你也是前端轉 DE,我的建議是:從你擅長的工具開始。
我用 Streamlit 而不是 Jupyter,因為我對「做出可互動的頁面」有直覺。每一頁的 st.selectbox + st.plotly_chart 都是我熟悉的 UI pattern,但背後的 pl.read_parquet() + pl.filter() + pl.group_by() 是新的。
Tech Stack
工具 | 用途 |
|---|---|
Streamlit | Dashboard framework — 純 Python,30 行就能出一頁 |
Polars | DataFrame 操作 — Rust 引擎,比 Pandas 快 |
Plotly | 互動式圖表 — scatter、bar、heatmap、sankey |
Graphviz | DAG 視覺化 — 畫 Pipeline 依賴圖 |
Dagster | Pipeline 編排 — 8 個 Asset 的定義和排程 |
Parquet + Hive Partitioning | 儲存格式 — column-oriented + partition pruning |