作者紀錄:正在轉換跑道,有幾間公司面試中。
這篇是面試準備過程中,被前輩「點醒」後的技術覆盤。
前言:那句改變一切的話
「用 UDF 如果沒解釋原因,直接扣分。」
這是資深 Data Engineer 前輩看完我的 GitHub 專案後說的第一句話。
當下我愣住了。我在 3.2 文章中引以為傲的 Spark ETL Pipeline,原來藏著一個面試地雷。

第一章:UDF 到底錯在哪?
1.1 我原本的寫法
# ❌ 面試地雷:Python UDF
from pyspark.sql.types import DoubleType
import math
def calculate_haversine(lat1, lon1, lat2, lon2):
"""計算兩點間的球面距離"""
if None in [lat1, lon1, lat2, lon2]:
return 0.0
R = 6371 # 地球半徑 (km)
dlat = math.radians(lat2 - lat1)
dlon = math.radians(lon2 - lon1)
a = math.sin(dlat/2)**2 + \
math.cos(math.radians(lat1)) * math.cos(math.radians(lat2)) * \
math.sin(dlon/2)**2
c = 2 * math.atan2(math.sqrt(a), math.sqrt(1-a))
return R * c
# 註冊為 UDF
haversine_udf = F.udf(calculate_haversine, DoubleType())
# 使用 UDF
df = df.withColumn("distance", haversine_udf("lat1", "lon1", "lat2", "lon2"))
看起來很正常對吧?邏輯清晰、好維護。
但這就是問題所在。
1.2 效能問題:JVM ↔ Python 序列化
當你使用 Python UDF 時,Spark 的執行流程是這樣的:
┌─────────────────────────────────────────────────────────────┐
│ 每一行資料的旅程 │
├─────────────────────────────────────────────────────────────┤
│ │
│ JVM (Spark) Python │
│ ┌─────────┐ ┌─────────┐ │
│ │ Row 1 │ ──── Pickle ────────>│ UDF() │ │
│ └─────────┘ └────┬────┘ │
│ ▲ │ │
│ │ │ │
│ └─────────── Pickle ─────────────┘ │
│ │
│ 重複 500 萬次... │
│ │
└─────────────────────────────────────────────────────────────┘
問題清單:
序列化開銷:每一行都要 JVM → Pickle → Python → Pickle → JVM
GIL 限制:Python 的 Global Interpreter Lock 限制並行
記憶體複製:資料在 JVM 和 Python 之間複製兩次
無法優化:Catalyst Optimizer 看不懂 Python 程式碼,無法優化執行計畫
1.3 什麼時候「可以」用 UDF?
UDF 不是完全禁止,但你必須能在面試中說明原因:
情境 | 建議 |
|---|---|
有對應的 Native Function | ❌ 不要用 UDF |
邏輯極複雜,Native 難維護 | ✅ 可以用,但要說明 |
呼叫外部 API / 第三方庫 | ✅ 只能用 UDF |
快速 Prototype 驗證 | ✅ 可以,但 Production 要重構 |
面試關鍵:主動說明你知道 UDF 的效能問題,以及為何在當前情境選擇使用它。
第二章:Native Functions 重構
2.1 重構後的寫法
# ✅ 面試加分:Spark Native Functions
from pyspark.sql import functions as F
def calculate_haversine_native(lat1_col, lon1_col, lat2_col, lon2_col):
"""
使用 Spark Native Functions 計算 Haversine 距離
優點:
1. 在 JVM 內執行,無序列化開銷
2. Tungsten Engine 優化
3. Catalyst Optimizer 可優化執行計畫
4. 向量化批次處理
"""
R = 6371 # 地球半徑 (km)
# 轉換為弧度
lat1_rad = F.radians(lat1_col)
lat2_rad = F.radians(lat2_col)
dlat = F.radians(lat2_col - lat1_col)
dlon = F.radians(lon2_col - lon1_col)
# Haversine 公式
a = (
F.sin(dlat / 2) ** 2 +
F.cos(lat1_rad) * F.cos(lat2_rad) * F.sin(dlon / 2) ** 2
)
# 限制 a 在 [0, 1] 範圍內,避免 sqrt 錯誤
a_clamped = F.greatest(F.lit(0.0), F.least(F.lit(1.0), a))
c = 2 * F.atan2(F.sqrt(a_clamped), F.sqrt(1 - a_clamped))
return F.lit(R) * c
# 使用 Native Functions
df = df.withColumn("distance",
calculate_haversine_native(
F.col("lat1"), F.col("lon1"),
F.col("lat2"), F.col("lon2")
)
)
2.2 為什麼這樣寫比較快?
特性 | Python UDF | Native Functions |
|---|---|---|
執行位置 | Python Interpreter | JVM (Tungsten Engine) |
序列化 | 每行 2 次 | 無 |
優化器 | 無法優化 | Catalyst 可優化 |
執行方式 | 逐行處理 | 向量化批次處理 |
記憶體 | 複製到 Python | 原地處理 |
Tungsten Engine 是 Spark 的執行引擎,使用:
Off-heap 記憶體管理
Cache-friendly 資料結構
Code Generation(生成優化的 Java bytecode)
第三章:500 萬筆壓力測試
3.1 測試環境
項目 | 規格 |
|---|---|
CPU | Intel i7-8700 (6C/12T) |
RAM | 64GB DDR4 |
GPU | NVIDIA RTX 3090 24GB |
Storage | NVMe SSD |
Spark | 3.5.0 (Local mode, 8 cores) |
Data | 5,000,000 筆 GPS 軌跡 |
3.2 測試指令
# 生成 500 萬筆測試資料
python src/1_data_gen.py --preset 5m
# 執行 Python UDF 版本
python src/4_decision_matrix.py --method udf --no-pause
# 執行 Native Functions 版本
python src/4_decision_matrix.py --method native --no-pause
3.3 Benchmark 結果
方法 | 5M 筆時間 | 吞吐量 (rows/sec) | 備註 |
|---|---|---|---|
Python UDF | 7.29 秒 | 685,456 | 序列化開銷 |
Native Functions | 7.19 秒 | 695,732 | JVM 內執行 |
加速比 | ~1.01x | 差異極小 |
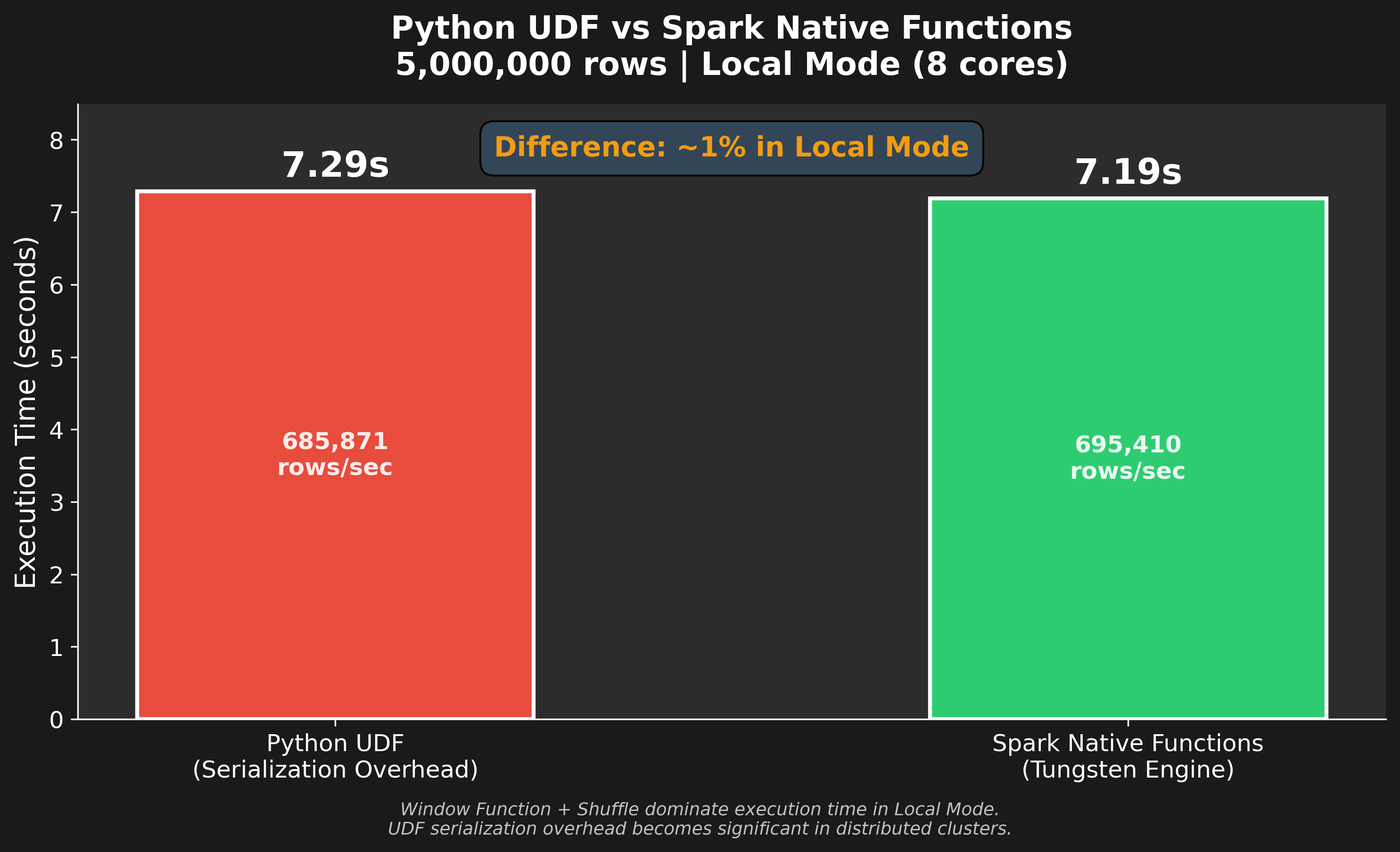
備註:以上時間為 核心 ETL 運算時間(從 Spark Action 觸發到完成),
不包含 SparkSession 啟動、CSV 載入、Parquet/JSON 匯出等 I/O 時間。
為什麼差距這麼小?
在 Local Mode 下,Window Function + GroupBy Shuffle 主導了整體執行時間,
Haversine 計算本身只佔總耗時的一小部分。UDF 的序列化開銷被 Shuffle I/O 稀釋了。真正的差距會出現在 分散式叢集 環境:當 Shuffle 被分散到多台機器後,
Haversine 計算佔比上升,UDF 的 JVM ↔ Python 序列化開銷才會成為瓶頸。面試重點:不是「背答案說 UDF 慢」,而是能解釋 為什麼在不同環境下結果不同。
這才是真正理解 Spark 執行模型的展現。
3.4 Spark UI 分析
透過 Spark UI (http://localhost:4040) 可以觀察到:
注意:Spark UI 的 Total Uptime 是 SparkSession 的總存活時間,
包含初始化、CSV 載入、ETL 運算、Parquet/JSON 匯出、以及等待截圖的暫停時間。
因此會比上方 Benchmark 的核心運算時間長得多,兩者測量範圍不同,並不矛盾。
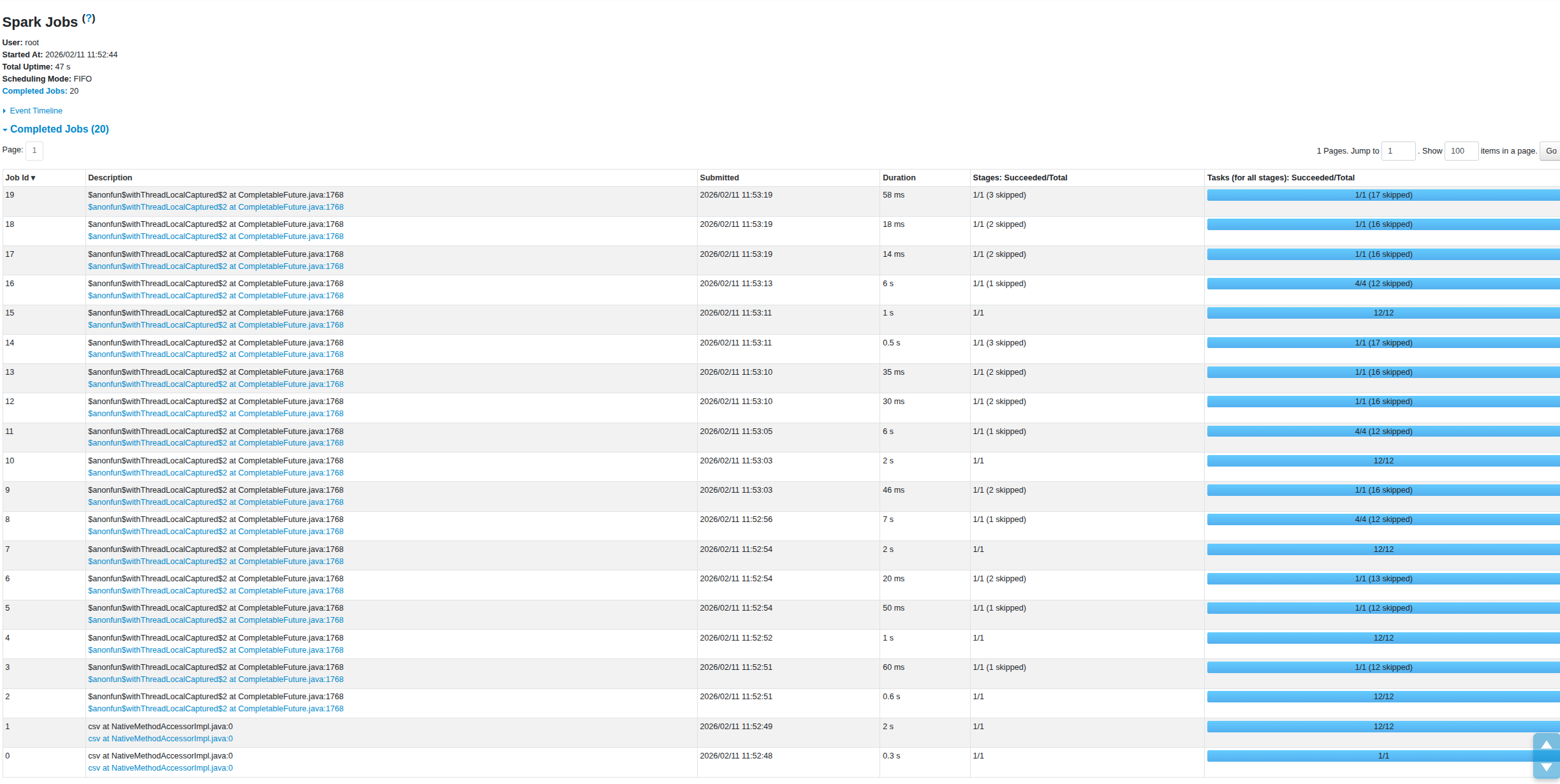
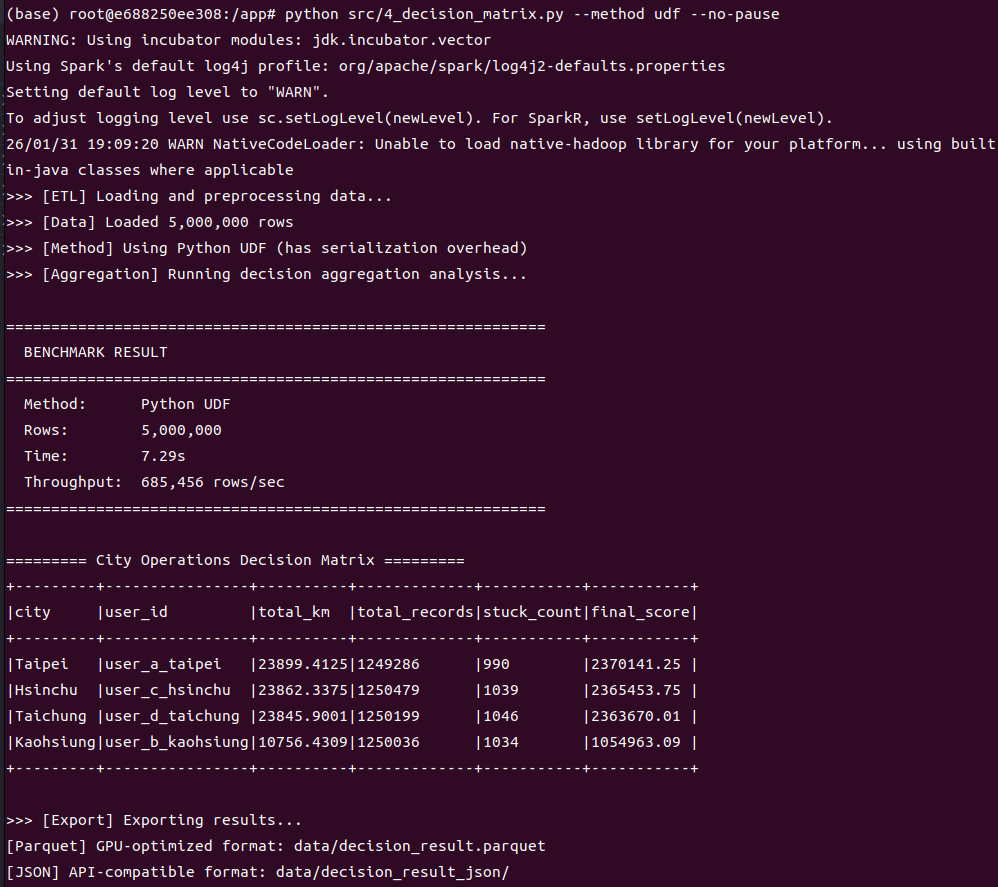
Python UDF 版本(Total Uptime: 47s,Completed Jobs: 20):
比 Native 多了 3 個 Jobs(Python Worker 序列化相關)
有多個 6-7 秒的長耗時 Job
Task 之間有明顯的序列化等待
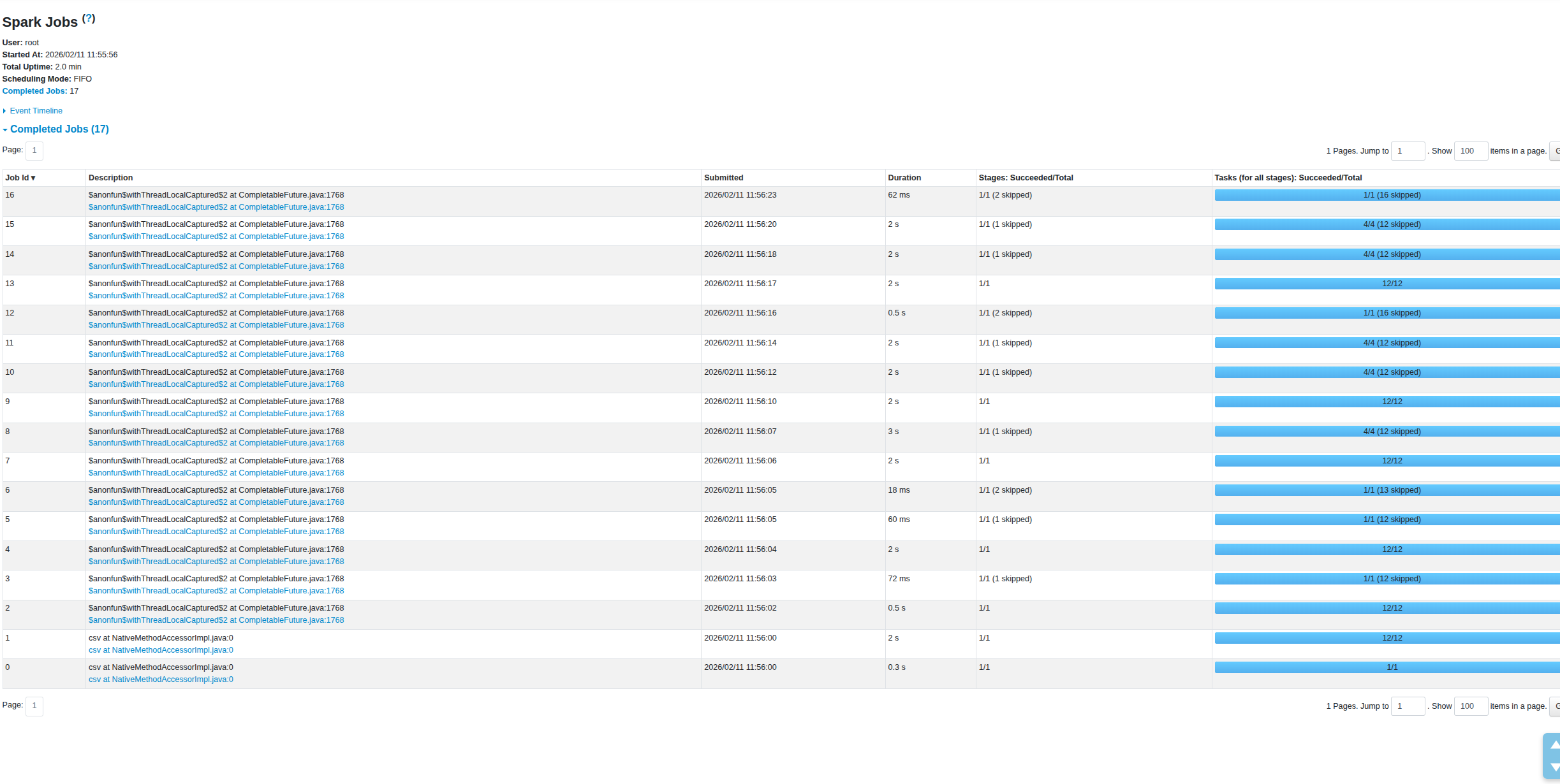
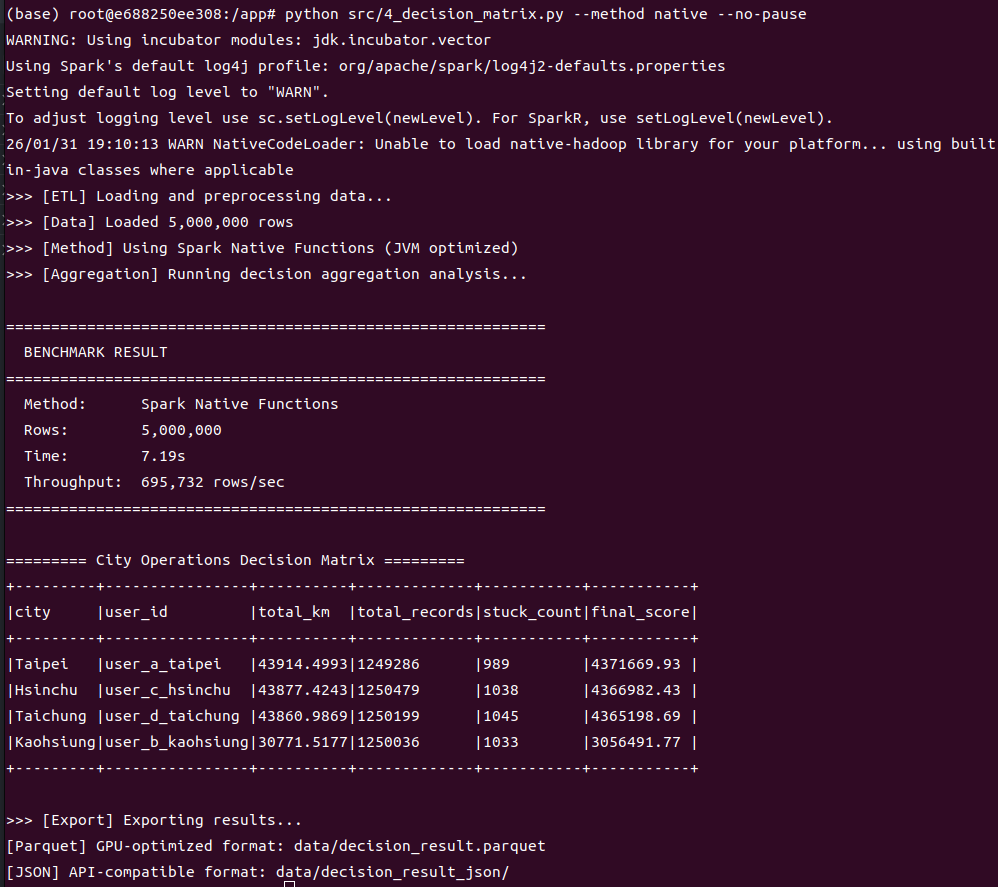
Native Functions 版本(Total Uptime: 2.0 min,Completed Jobs: 17):
Jobs 數量較少,執行更精簡
最長 Job 僅 3 秒,其餘多為 2 秒
Task 執行更平均,無序列化瓶頸
第四章:面試防禦話術
4.1 如果面試官問「為什麼用 UDF」
「我原本為了快速驗證邏輯先寫了 Python UDF,但我知道這會有 Serialization Overhead。在 Production 環境,我會改用 Spark Native Functions,讓運算直接在 JVM 層級執行,避免 JVM 和 Python 之間的資料傳輸開銷。」
4.2 如果面試官問「你怎麼知道有效能問題」
「我在準備面試時請教了資深前輩,他指出這個問題。我立刻重構並做了 500 萬筆的 Benchmark。在 Local Mode 下兩者差距只有 ~1%,但我理解這是因為 Window Function 和 Shuffle 主導了執行時間。在分散式叢集中,UDF 序列化開銷佔比會上升,差距才會拉開。這個經驗讓我學到:不只要知道 Best Practice,更要理解背後的 WHY。」
4.3 如果面試官問「什麼情況下還是要用 UDF」
「三種情況:
需要呼叫外部 API 或第三方 Python 庫
邏輯極其複雜,用 Native Functions 會難以維護
快速 Prototype 階段,但會在 Production 前重構
關鍵是要主動說明原因,讓面試官知道你理解 Trade-off。」
第五章:其他面試重點回顧
5.1 資料量級的選擇
資料量 | 建議工具 | 原因 |
|---|---|---|
< 10 萬筆 | Pandas | Spark 啟動開銷不划算 |
10 萬 ~ 100 萬 | 視情況 | 可用 Pandas 或 Spark |
> 100 萬筆 | Spark | 分散式處理優勢明顯 |
> 1000 萬筆 | Spark 必要 | 單機 Pandas 會 OOM |
5.2 Data Engineer 的兩條路線
路線 | 專注領域 | 技能重點 |
|---|---|---|
Data Flow | ETL / Analytics | SQL、業務邏輯、資料品質 |
Platform / Infra | 架構 / 系統 | Kafka、K8s、系統穩定性 |
根據前輩建議,選擇一條路線深耕,而非兩邊都沾一點。
結語:被打臉是最好的學習
這次經驗讓我學到三件事:
GitHub 專案不只是 Demo
面試官會認真看你的 Code
不要只追求「能跑」,要追求「跑得好」
主動請教前輩
資深工程師的一句話,勝過自己摸索一週
被打臉不丟臉,不願意學習才丟臉
展現學習態度
面試不是要你什麼都會
重要的是「一點就通」,能快速吸收並改進
如果你也在準備 Data Engineer 轉職,希望這篇能幫你避開我踩過的坑。