背景:一個持續存在的技術疑問
在處理即時地圖服務時,我們遇到一個問題:系統在測試環境表現穩定,但在生產環境遇到尖峰流量時會出現記憶體溢出。當時團隊採用 Node.js 處理地圖軌跡資料,並使用隨機抽樣進行驗證。
這個方法在理論上是合理的——既然無法處理全量資料,抽樣是常見的做法。但我一直在思考:如果只檢視樣本,那些存在於長尾數據中的極端案例會不會被遺漏?
事實證明了這個疑慮。抽樣確實讓我們忽略了關鍵的異常叢聚,導致決策判斷失準。
為了驗證這個假設,我在個人專案 Geo Decision Matrix 中設計了一個對照實驗,用實際的代碼和壓力測試來確認:單機架構的物理極限在哪裡?分散式架構能提供什麼優勢?
延伸閱讀:
🔗 第一篇:倖存者偏差如何差點毀掉我們的決策引擎(中文)
🔗 Part 1: How Survivorship Bias Nearly Destroyed Our Decision Engine(英文)
實驗設計:系統架構對照
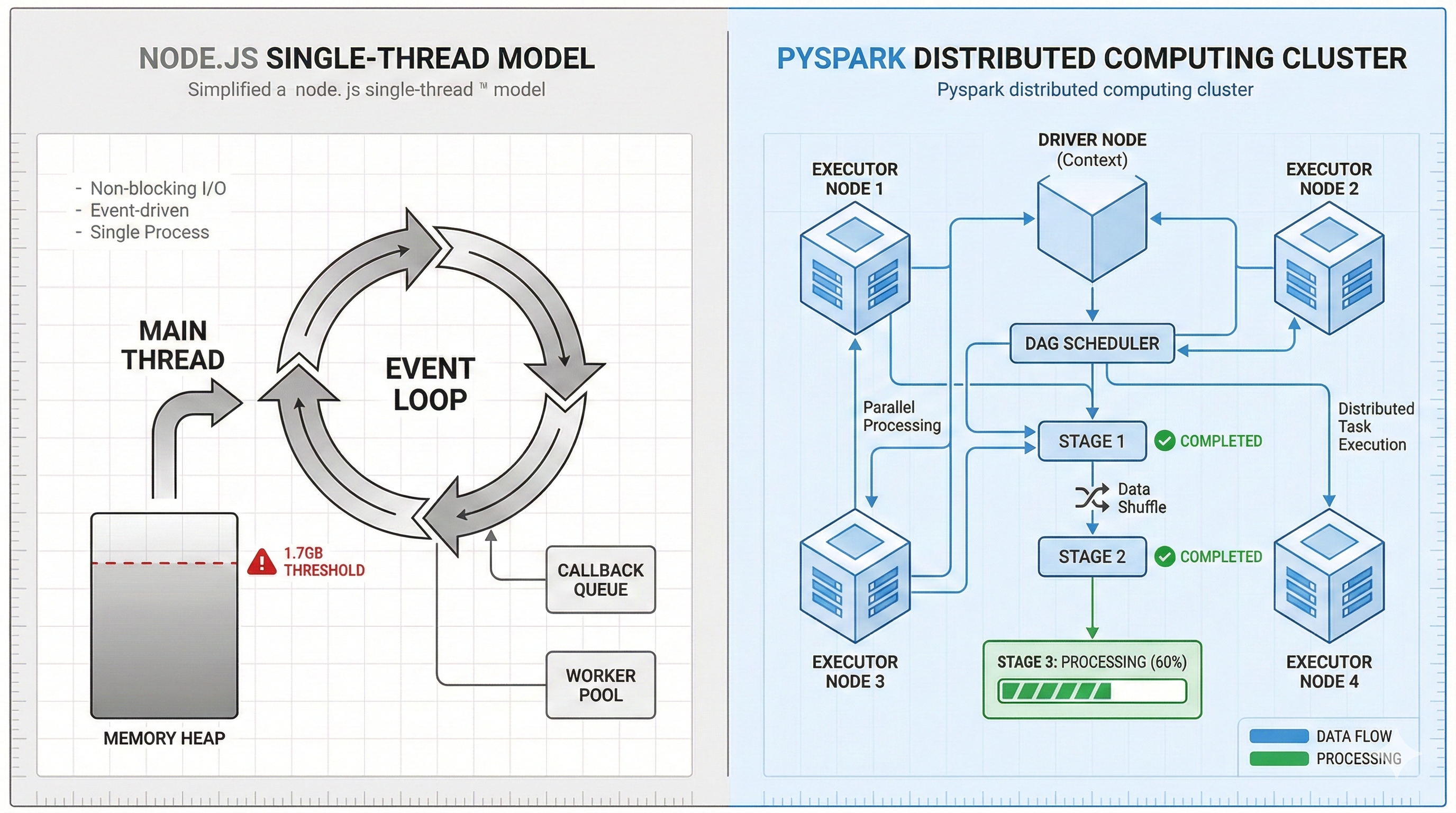
為了系統化地比較兩種架構,我繪製了以下對照圖:

[圖 1:左側 Node.js 單點架構;右側 Spark 分散式架構]
實驗一:Node.js 單機架構的記憶體瓶頸
為了重現問題,我撰寫了 legacy_benchmark.js,模擬典型的實作方式:一次讀取 50 萬筆 CSV 資料,並以非同步方式模擬外部 API 呼叫。
問題程式碼
// src/legacy_benchmark.js
const runBenchmark = async () => {
// ... 讀取 CSV ...
const promises = [];
// 關鍵問題:瞬間產生 50 萬個 Pending Promise
// V8 Heap 無法即時回收
for (let i = 0; i < lines.length; i++) {
const record = parse(lines[i]);
promises.push(mockExternalApiCall(record));
}
console.log(">>> 等待所有 API 回應...");
await Promise.all(promises);
};
實驗結果
在記憶體限制為 512MB (--max-old-space-size=512) 的條件下執行:
執行時間:3.2 秒(崩潰前)
記憶體使用:1.7GB(Heap Used)
結果:FATAL ERROR - Out of Memory

[圖 2:終端機顯示 OOM 錯誤訊息]
數據顯示,Node.js 的單執行緒 Event Loop 在面對大量非同步任務時,垃圾回收速度跟不上物件產生的速度。即使增加 RAM,只要工作負載增長速度超過 GC 速度,問題仍然存在。
實驗二:PySpark 分散式架構的穩定性測試
接著,我將相同的運算邏輯移植到 Docker + PySpark 環境。除了使用分散式運算,我還加入了一個數學防禦機制。
浮點數精度問題的處理
在過去的經驗中,我發現當兩點座標完全重疊時(距離為 0),浮點數運算誤差會導致 acos(1.00000002),產生 NaN 值,使整張報表失效。
# src/4_decision_matrix.py
def calculate_haversine(lat1, lon1, lat2, lon2):
# ... 省略三角函數宣告 ...
# Haversine 公式計算
a = math.sin(dlat/2)**2 + \
math.cos(lat1) * math.cos(lat2) * math.sin(dlon/2)**2
# 防止浮點數誤差
# 當 a 稍微大於 1.0 時,asin(sqrt(a)) 會產生 NaN
a = min(1.0, max(0.0, a))
c = 2 * math.atan2(math.sqrt(a), math.sqrt(1-a))
return R * c
實驗結果
相同的 50 萬筆資料、相同的運算邏輯:
執行時間:19.88 秒
記憶體曲線:穩定
結果:成功完成,輸出 JSON 報表

[圖 3:終端機顯示 real 0m19.88s]
雖然執行時間較 Node.js 崩潰前的 3.2 秒長,但多出的時間用於:
JVM 啟動
資源隔離
DAG 優化
系統不僅穩定完成全量資料處理,記憶體使用量也保持在可控範圍。
技術分析:Spark 的執行機制
開啟 Spark UI 可以清楚看到任務拆解過程:

[圖 4:藍色 Exchange 階段顯示 Shuffle 機制]
關鍵機制
Lazy Evaluation(惰性運算)
Spark 不會立即執行運算,而是先建構 DAG,在最後一刻才執行。這避免了 Node.js 將所有任務同時載入記憶體的問題。Shuffle(資料重分配)
在 Exchange 階段,Spark 自動將資料切分並分發給不同的 Executor,實現分散式運算。Shuffle Reuse(階段重用)
Log 中顯示部分 Stage 被跳過(Skipped),表示 Spark 重用了中間運算結果,避免重複計算。
實驗結論
這次實驗讓我確認了幾個觀察:
工具適用性
Node.js 在高併發 Web 請求場景表現良好,但不適合大數據的 ETL 處理。Spark 雖然啟動較重,但提供了可預測性和容錯能力。架構選擇的權衡
在面對大量資料處理時,系統的穩定性往往比峰值效能更重要。能穩定完成全量處理(19.88秒),通常比極速但會崩潰的方案(3.2秒後 OOM)更有實際價值。數學防禦的必要性
在處理地理座標運算時,浮點數精度問題可能導致不易察覺的錯誤。適當的邊界檢查可以避免 NaN 值破壞整個資料處理流程。
Repository
完整程式碼已上傳至 GitHub:https://github.com/BlakeHung/geo-decision-matrix
後續計畫:下一篇將展示如何將這些運算結果,透過 AI 分群與視覺化地圖,轉化為具有商業決策價值的分析矩陣。
系列文章
📖 第一篇:倖存者偏差如何差點毀掉我們的決策引擎(中文)
📖 Part 1: How Survivorship Bias Nearly Destroyed Our Decision Engine(英文)
📖 第二篇:從生產環境問題到架構重構(本文)