Background: A Persistent Technical Question
While working on a real-time mapping service, we encountered a recurring issue: the system performed well in the test environment but experienced memory overflow during peak traffic in production. At the time, our team used Node.js to process map trajectory data and employed random sampling for validation.
This approach seemed reasonable in theory—if we couldn't process the full dataset, sampling was a common practice. However, I kept thinking: if we only examine samples, what about edge cases hidden in the long-tail data? Could they be overlooked?
This concern proved valid. The sampling approach did cause us to miss critical anomaly clusters, leading to inaccurate decision-making.
To verify this hypothesis, I designed a controlled experiment in my personal project, Geo Decision Matrix, using actual code and stress testing to confirm: Where are the physical limits of single-machine architecture? What advantages does distributed architecture provide?
Related Reading:
🔗 Part 1: How Survivorship Bias Nearly Destroyed Our Decision Engine (Chinese)
🔗 Part 1: How Survivorship Bias Nearly Destroyed Our Decision Engine (English)
Experiment Design: System Architecture Comparison
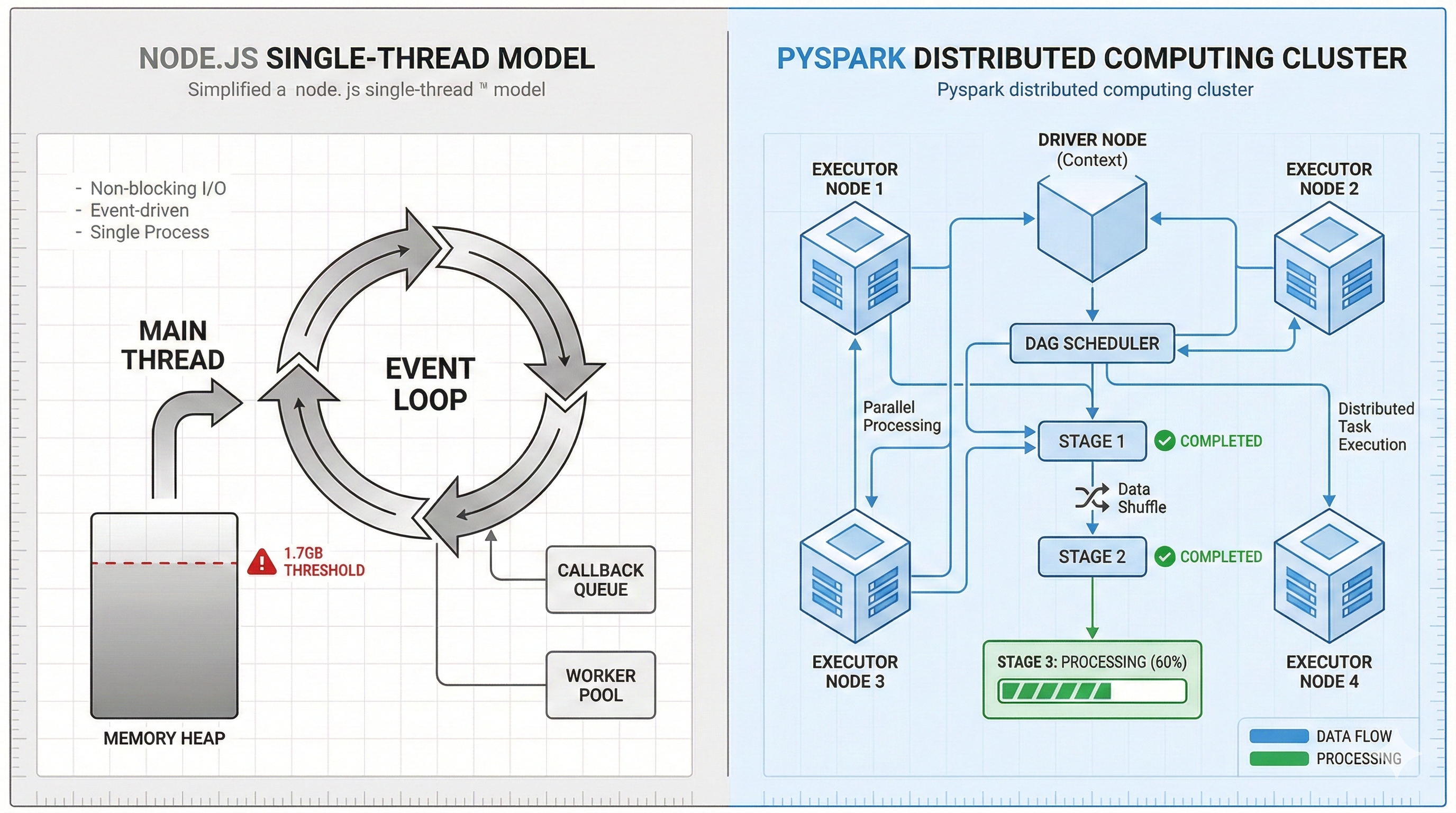
To systematically compare the two architectures, I created the following comparison diagram:

[Figure 1: Left - Node.js single-point architecture; Right - Spark distributed architecture]
Experiment 1: Node.js Single-Machine Architecture Memory Bottleneck
To reproduce the issue, I wrote legacy_benchmark.js to simulate a typical implementation: reading 500,000 CSV records at once and using asynchronous methods to simulate external API calls.
Problem Code
// src/legacy_benchmark.js
const runBenchmark = async () => {
// ... Read CSV ...
const promises = [];
// Critical issue: Instantly generating 500,000 pending promises
// V8 Heap cannot reclaim memory in time
for (let i = 0; i < lines.length; i++) {
const record = parse(lines[i]);
promises.push(mockExternalApiCall(record));
}
console.log(">>> Waiting for all API responses...");
await Promise.all(promises);
};
Experiment Results
Running with a 512MB memory limit (--max-old-space-size=512):
Execution Time: 3.2 seconds (before crash)
Memory Usage: 1.7GB (Heap Used)
Result: FATAL ERROR - Out of Memory

[Figure 2: Terminal showing OOM error message]
The data shows that Node.js's single-threaded Event Loop, when facing a large number of asynchronous tasks, cannot keep up with the object creation rate through garbage collection. Even with more RAM, if the workload growth rate exceeds the GC rate, the problem persists.
Experiment 2: PySpark Distributed Architecture Stability Test
Next, I ported the same computation logic to a Docker + PySpark environment. In addition to using distributed computing, I added a mathematical safeguard mechanism.
Handling Floating-Point Precision Issues
In past experience, I found that when two coordinate points completely overlap (distance of 0), floating-point computation errors can cause acos(1.00000002), producing NaN values that invalidate the entire report.
# src/4_decision_matrix.py
def calculate_haversine(lat1, lon1, lat2, lon2):
# ... Omitted trigonometric function declarations ...
# Haversine formula calculation
a = math.sin(dlat/2)**2 + \
math.cos(lat1) * math.cos(lat2) * math.sin(dlon/2)**2
# Prevent floating-point errors
# When a is slightly greater than 1.0, asin(sqrt(a)) will produce NaN
a = min(1.0, max(0.0, a))
c = 2 * math.atan2(math.sqrt(a), math.sqrt(1-a))
return R * c
Experiment Results
Same 500,000 records, same computation logic:
Execution Time: 19.88 seconds
Memory Curve: Stable
Result: Successfully completed, output JSON report

[Figure 3: Terminal showing real 0m19.88s]
Although the execution time is longer than the 3.2 seconds before Node.js crashed, the additional time is spent on:
JVM startup
Resource isolation
DAG optimization
The system not only stably completed the full dataset processing but also maintained memory usage within a controllable range.
Technical Analysis: Spark's Execution Mechanism
Opening the Spark UI clearly shows the task decomposition process:

[Figure 4: Blue Exchange stage showing Shuffle mechanism]
Key Mechanisms
Lazy Evaluation
Spark doesn't execute computations immediately but first constructs a DAG, executing only at the last moment. This avoids Node.js's problem of loading all tasks into memory simultaneously.Shuffle (Data Redistribution)
In the Exchange stage, Spark automatically partitions and distributes data to different Executors, achieving distributed computing.Shuffle Reuse (Stage Reuse)
The log shows some stages were skipped, indicating Spark reused intermediate computation results, avoiding redundant calculations.
Experiment Conclusions
This experiment confirmed several observations:
Tool Applicability
Node.js performs well in high-concurrency web request scenarios but is not suitable for large-scale data ETL processing. While Spark has a heavier startup, it provides predictability and fault tolerance.Architecture Trade-offs
When processing large datasets, system stability often matters more than peak performance. Stable completion of full processing (19.88 seconds) typically has more practical value than a solution that's fast but crashes (3.2 seconds then OOM).Necessity of Mathematical Safeguards
When processing geographic coordinate calculations, floating-point precision issues can lead to undetectable errors. Appropriate boundary checks can prevent NaN values from disrupting the entire data processing pipeline.
Repository
Complete code available on GitHub: https://github.com/BlakeHung/geo-decision-matrix
Next Steps: The next article will demonstrate how to transform these computation results into business decision-valuable analysis matrices through AI clustering and visualization maps.
Related Articles in This Series
📖 Part 1: How Survivorship Bias Nearly Destroyed Our Decision Engine (Chinese)
📖 Part 1: How Survivorship Bias Nearly Destroyed Our Decision Engine (English)
📖 Part 2: From Production Issues to Architecture Redesign (This article)