作者紀錄:這篇遲了點。最近正在轉換跑道,目前有幾間公司正在面試中,更新速度慢了些。在準備面試的過程中,也收到前輩針對 3.2 的技術回饋,會在下一篇 3.4 詳細分享重構心得。
前言:三部曲的最終章
在前兩篇文章中,我們經歷了:
3.1 硬體限制篇:雙 RTX 3090 因缺少 NVLink,多卡反而比單卡慢 2.8 倍
3.2 混合架構篇:Spark (CPU) + RAPIDS (GPU) 的接力賽模式,150 秒完成全量分析
但還有一個問題沒解決:即時推論。
當 API 需要即時查詢單一司機的風險評估時,啟動 Spark Context 的 Overhead 太高。這就像「開砂石車去便利商店買水」——殺雞焉用牛刀。
這篇文章要解決的就是這個問題:如何讓 GPU 推論從 15 秒降到 0.25 秒?
答案是:微服務重構 + 模型熱啟動。
第一章:依賴地獄的根源
1.1 曾經的噩夢
在專案初期,為了「一個容器搞定所有事」,我的 Dockerfile 長這樣:
# ❌ 依賴地獄的起點
FROM python:3.10-slim
# Java(給 Spark 用)
RUN apt-get update && apt-get install -y openjdk-17-jdk
# Scala(給 Spark SQL 用)
RUN apt-get install -y scala
# Python AI 依賴
RUN pip install torch transformers pyspark
# 結果:Image 大小超過 5GB
# JVM 和 Python 環境變數互相干擾
# 維護極其痛苦
問題清單:
體積肥大:一個 Docker Image 超過 5GB,CI/CD 每次都要等半小時
環境衝突:Java 和 Python 的環境變數互相覆蓋
啟動延遲:每次 API 請求都要初始化 Spark Context(~15 秒)
1.2 關鍵決策:斷捨離
解決方案只有一個字:拆。
Spark 負責批次處理(3.2 的 ETL 流程)
Celery 負責即時推論(本篇的微服務架構)
兩者各司其職,不再混在一起
第二章:微服務架構設計
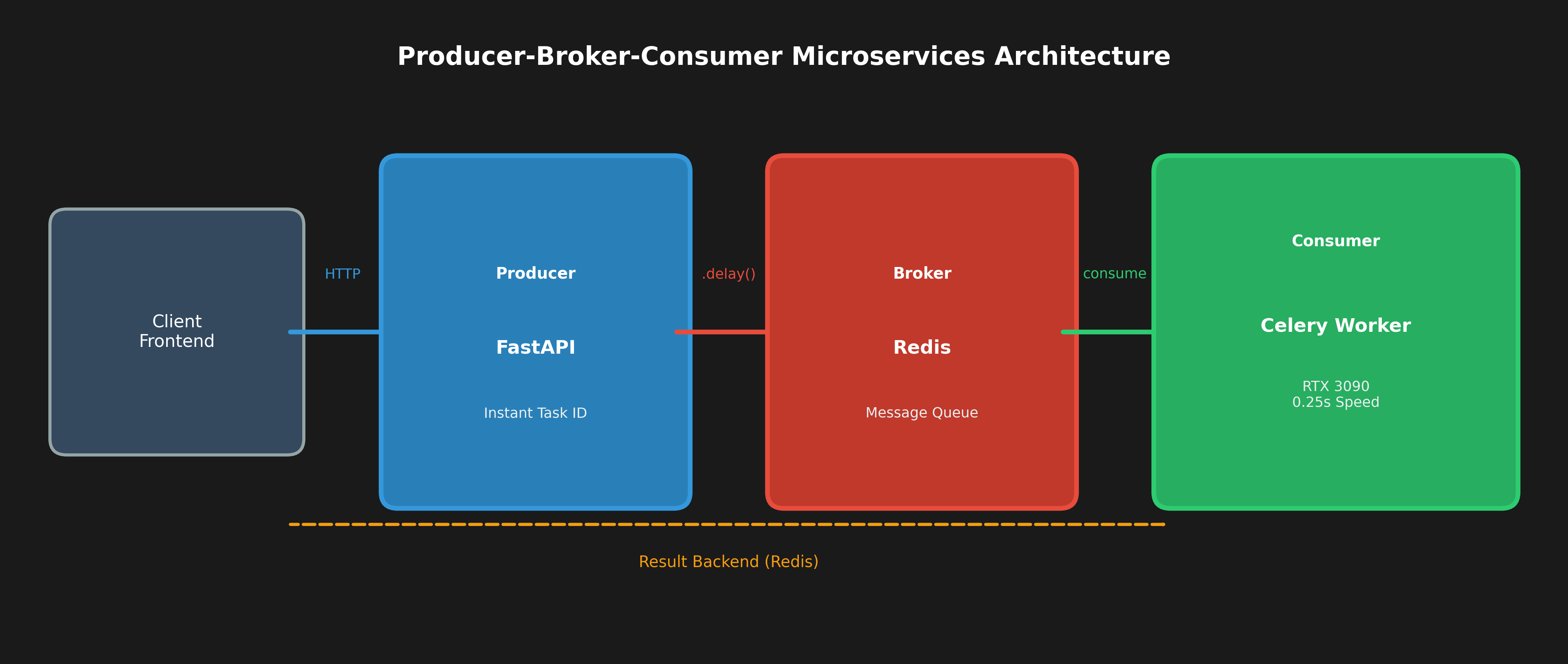
2.1 Producer-Broker-Consumer 模式
這是經典的非同步任務處理模式:
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ FastAPI │ .delay │ Redis │ consume │ Celery │
│ (Producer) │ ──────> │ (Broker) │ ──────> │ (GPU) │
└─────────────┘ └─────────────┘ └─────────────┘
│ │
│ Result Backend │
└<─────────────────────────────────────────────┘
關鍵優勢:
非同步解耦:API 不等待 GPU 運算完成,立即回傳 Task ID
水平擴展:可以啟動多個 Celery Worker 分散負載
故障隔離:GPU Worker 崩潰不影響 API 服務
2.2 FastAPI Producer 實作
# src/api.py
from fastapi import FastAPI
from pydantic import BaseModel
from celery.result import AsyncResult
from celery_worker import celery_app, analyze_driver_task
app = FastAPI(title="Geo Decision Matrix AI Core")
class DriverRequest(BaseModel):
driver_id: str
speed: float = 50.0 # 平均速度 (km/h)
stuck_count: int = 0 # 卡住次數
@app.post("/analyze")
async def analyze_driver(request: DriverRequest):
"""
這是「秒回」的關鍵:
API 不等待 GPU 運算,直接回傳 Task ID
"""
task = analyze_driver_task.delay(
request.driver_id,
request.speed,
request.stuck_count
)
return {
"message": "Task submitted to GPU queue",
"task_id": task.id,
"check_url": f"/result/{task.id}"
}
@app.get("/result/{task_id}")
async def get_result(task_id: str):
"""
前端透過 Task ID 輪詢結果
"""
task_result = AsyncResult(task_id, app=celery_app)
if task_result.state == 'PENDING':
return {"status": "Pending", "progress": "Waiting for GPU..."}
elif task_result.state == 'SUCCESS':
return {"status": "Success", "result": task_result.result}
elif task_result.state == 'FAILURE':
return {"status": "Failure", "error": str(task_result.result)}
使用體驗:
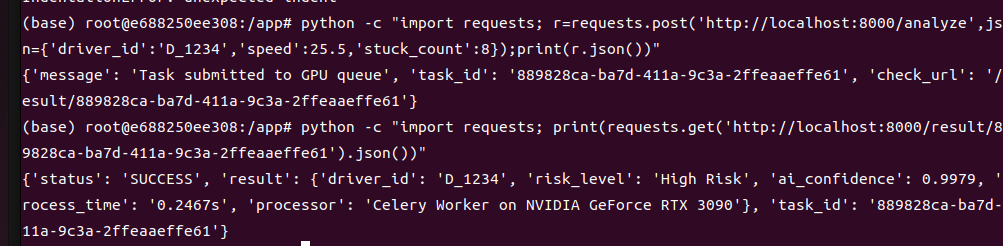
# 1. 發送請求(瞬間回應)
$ curl -X POST http://localhost:8000/analyze \
-H "Content-Type: application/json" \
-d '{"driver_id": "D_1234", "speed": 25.5, "stuck_count": 8}'
{
"message": "Task submitted to GPU queue",
"task_id": "abc123-def456-...",
"check_url": "/result/abc123-def456-..."
}
# 2. 輪詢結果(GPU 運算完成後)
$ curl http://localhost:8000/result/abc123-def456-...
{
"status": "Success",
"result": {
"driver_id": "D_1234",
"risk_level": "High Risk",
"ai_confidence": 0.9876,
"process_time": "0.5123s",
"processor": "Celery Worker on NVIDIA GeForce RTX 3090"
}
}
第三章:0.2467 秒的秘密——模型熱啟動
3.1 Cold Start vs Hot Start
這是整篇文章最重要的技術點。
Cold Start(冷啟動):
# ❌ 每次請求都載入模型
@app.task
def analyze_driver(driver_id):
# 這行每次執行都要 10-15 秒
model = pipeline("sentiment-analysis", device=0)
result = model(f"Driver {driver_id}...")
return result
Hot Start(熱啟動):
# ✅ 模型在 Worker 啟動時載入一次
# Global Scope - 只執行一次
model = pipeline("sentiment-analysis", device=0)
@app.task
def analyze_driver(driver_id):
# 直接使用已載入的模型(~0.25秒)
result = model(f"Driver {driver_id}...")
return result
效能對比:
模式 | 首次請求 | 後續請求 | 原因 |
|---|---|---|---|
Cold Start | 15 秒 | 15 秒 | 每次都要載入模型到 GPU |
Hot Start | 15 秒 | 0.25秒 | 模型常駐 GPU 記憶體 |
3.2 Celery Worker 完整實作
# src/celery_worker.py
import os
import time
import torch
from celery import Celery
from transformers import pipeline
# ==========================================
# 1. Celery 配置
# ==========================================
CELERY_BROKER_URL = 'redis://localhost:6379/0'
CELERY_RESULT_BACKEND = 'redis://localhost:6379/0'
celery_app = Celery('geo_ai_worker',
broker=CELERY_BROKER_URL,
backend=CELERY_RESULT_BACKEND)
# ==========================================
# 2. 模型熱啟動(關鍵!)
# ==========================================
# 這段代碼在 Worker 啟動時執行一次
# 模型會常駐在 GPU 記憶體中
print("⏳ [System] 正在初始化 AI 模型 (Warm Start)...")
device_id = 0 if torch.cuda.is_available() else -1
device_name = torch.cuda.get_device_name(0) if device_id != -1 else "CPU"
# 載入模型到 GPU
risk_analyzer = pipeline(
"sentiment-analysis",
model="distilbert-base-uncased-finetuned-sst-2-english",
device=device_id
)
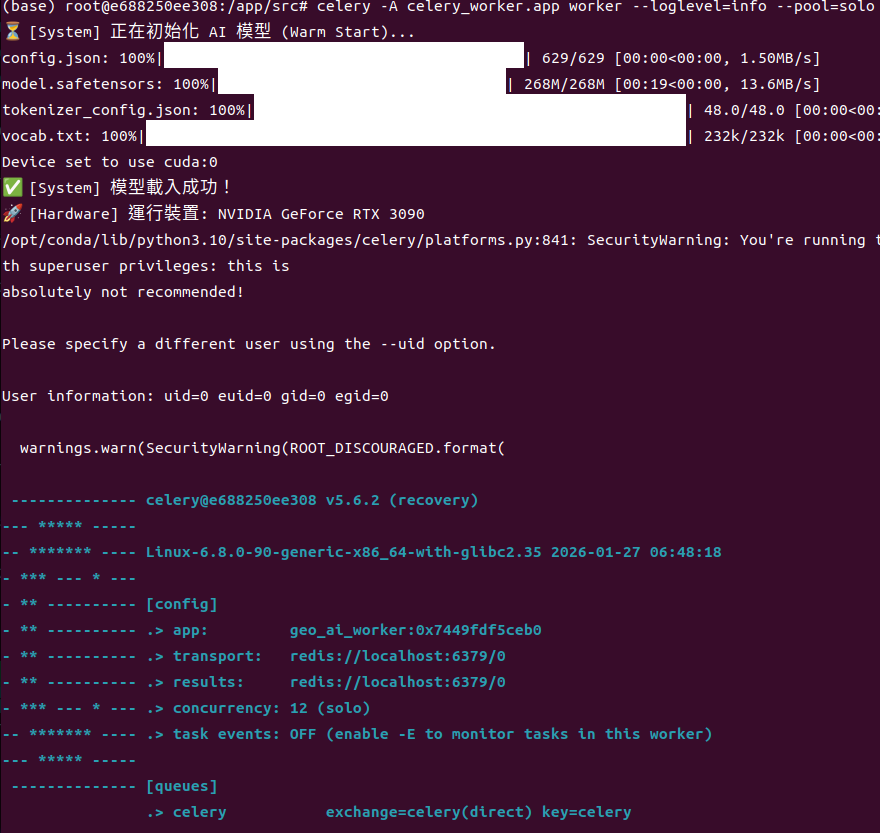
print(f"✅ [System] 模型載入成功!")
print(f"🚀 [Hardware] 運行裝置: {device_name}")
# ==========================================
# 3. 任務定義
# ==========================================
@celery_app.task(bind=True, name='analyze_driver_task')
def analyze_driver_task(self, driver_id, speed=50.0, stuck_count=0):
"""
GPU 推論任務
使用已載入的模型,避免 Cold Start
"""
start_time = time.time()
# 將數據轉為語意文本
context_text = f"Driver {driver_id} is driving at {speed} km/h and got stuck {stuck_count} times."
# GPU 推論(~0.5秒)
result = risk_analyzer(context_text)[0]
risk_level = "High Risk" if result['label'] == "NEGATIVE" else "Safe"
process_time = time.time() - start_time
return {
"driver_id": driver_id,
"risk_level": risk_level,
"ai_confidence": round(result['score'], 4),
"process_time": f"{process_time:.4f}s",
"processor": f"Celery Worker on {device_name}"
}
3.3 終端機輸出——高光時刻
當你啟動 Celery Worker 時,會看到:
當收到任務時:
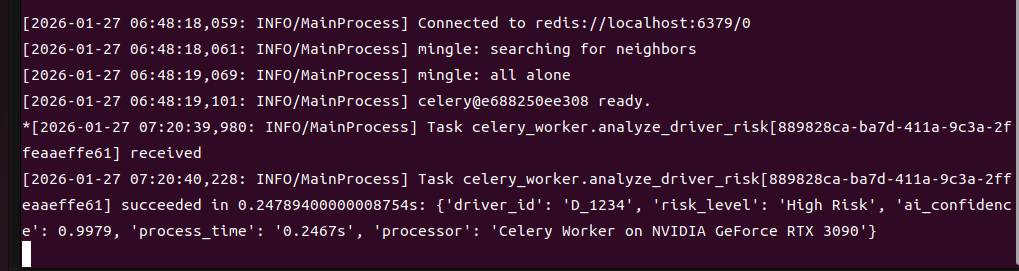
那個 0.2467s,就是我們追求的 0.25 秒極速。
第四章:Docker GPU 穿透實戰
4.1 NVIDIA Container Toolkit
讓 Docker 容器「看見」宿主機的 GPU,需要安裝 NVIDIA Container Toolkit:
# Ubuntu/Debian
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | \
sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
sudo systemctl restart docker
4.2 docker-compose.yml 配置
# docker-compose.yml
services:
geo-ai:
build: .
container_name: geo_decision_matrix
volumes:
- .:/app
ports:
- "9090:8000" # API 端口
extra_hosts:
- "host.docker.internal:host-gateway" # 連接宿主機服務
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all # 使用所有 GPU
capabilities: [gpu] # 啟用 GPU 能力
關鍵配置解釋:
配置 | 用途 |
|---|---|
| 使用 NVIDIA GPU 驅動 |
| 映射所有可用的 GPU |
| 啟用 GPU 計算能力 |
| 讓容器能連接宿主機的 Ollama 等服務 |
4.3 Dockerfile 瘦身後
# Dockerfile(瘦身版)
FROM rapidsai/base:23.10-cuda11.8-py3.10
USER root
# 系統依賴(只裝必要的)
RUN apt-get update && \
apt-get install -y redis-server libgl1 && \
rm -rf /var/lib/apt/lists/*
# Python 依賴(無 Java!)
RUN pip install --no-cache-dir \
pyspark pandas numpy pyarrow \
torch transformers accelerate \
fastapi uvicorn \
celery[redis] redis
WORKDIR /app
COPY . /app
CMD ["bash"]
對比:
Before:5GB+(含 Java、Scala、完整 Spark)
After:~2GB(純 Python + CUDA)
4.4 WSL 2 特殊處理
如果你在 WSL 2 環境下運行,需要額外配置:
# 在 celery_worker.py 開頭加入
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0" # 只使用第一張 GPU
os.environ["NCCL_P2P_DISABLE"] = "1" # 關閉 NCCL P2P(WSL 2 不支援)
原因:WSL 2 的 GPU 虛擬化不支援 NCCL P2P,會導致 ncclSystemError。
第五章:完整啟動流程
5.1 一鍵啟動腳本
#!/bin/bash
# run_microservices.sh
echo "🚀 Starting Geo Decision Matrix Microservices..."
# Step 1: 啟動 Redis(Message Broker)
echo "🔴 Starting Redis..."
redis-server --daemonize yes
# Step 2: 啟動 Celery Worker(GPU Consumer)
echo "🟢 Starting Celery Worker (GPU)..."
cd src
celery -A celery_worker.celery_app worker --loglevel=info --pool=solo &
# 等待模型載入
sleep 5
# Step 3: 啟動 FastAPI(API Producer)
echo "🔵 Starting FastAPI..."
uvicorn api:app --host 0.0.0.0 --port 8000 --reload
5.2 測試腳本
#!/bin/bash
# test_gpu_inference.sh
echo "🧪 Testing GPU Inference..."
# 發送測試請求
RESPONSE=$(curl -s -X POST http://localhost:8000/analyze \
-H "Content-Type: application/json" \
-d '{"driver_id": "D_1234", "speed": 25.5, "stuck_count": 8}')
TASK_ID=$(echo $RESPONSE | jq -r '.task_id')
echo "Task ID: $TASK_ID"
# 輪詢結果
for i in {1..10}; do
RESULT=$(curl -s http://localhost:8000/result/$TASK_ID)
STATUS=$(echo $RESULT | jq -r '.status')
if [ "$STATUS" == "Success" ]; then
echo "✅ GPU Inference Complete!"
echo $RESULT | jq
break
fi
sleep 1
done
效能總結
三部曲效能對比
階段 | 架構 | 單次請求時間 | 適用場景 |
|---|---|---|---|
3.1 | 雙 GPU 分散式 | 420 秒 | ❌ 失敗 |
3.2 | Spark + RAPIDS 混合 | 150 秒 | ✅ 批次處理 |
3.3 | 微服務 + 熱啟動 | 0.2467 秒 | ✅ 即時推論 |
關鍵技術總結
Producer-Broker-Consumer:非同步解耦,API 秒回
模型熱啟動:Global Scope 載入,避免 Cold Start
Docker GPU 穿透:NVIDIA Container Toolkit 配置
WSL 2 特殊處理:關閉 NCCL P2P
結語:從依賴地獄到算力解放
回顧這個三部曲的旅程:
3.1:硬體的物理限制教會我——不是 GPU 越多越好
3.2:混合架構教會我——讓對的硬體做對的事
3.3:微服務重構教會我——架構設計比堆料更重要
最終,我們實現了:
批次處理:150 秒完成 50 萬筆 GPS 數據分析
即時推論:0.25 秒完成單一駕駛風險評估
當你看到終端機印出 Device: NVIDIA GeForce RTX 3090 的那一刻,你就知道——算力已經解放了。
附錄:視覺化圖表
圖 1:微服務架構圖
展示 Client → FastAPI → Redis → Celery (GPU) 的完整資料流。
圖 2:推論時間對比
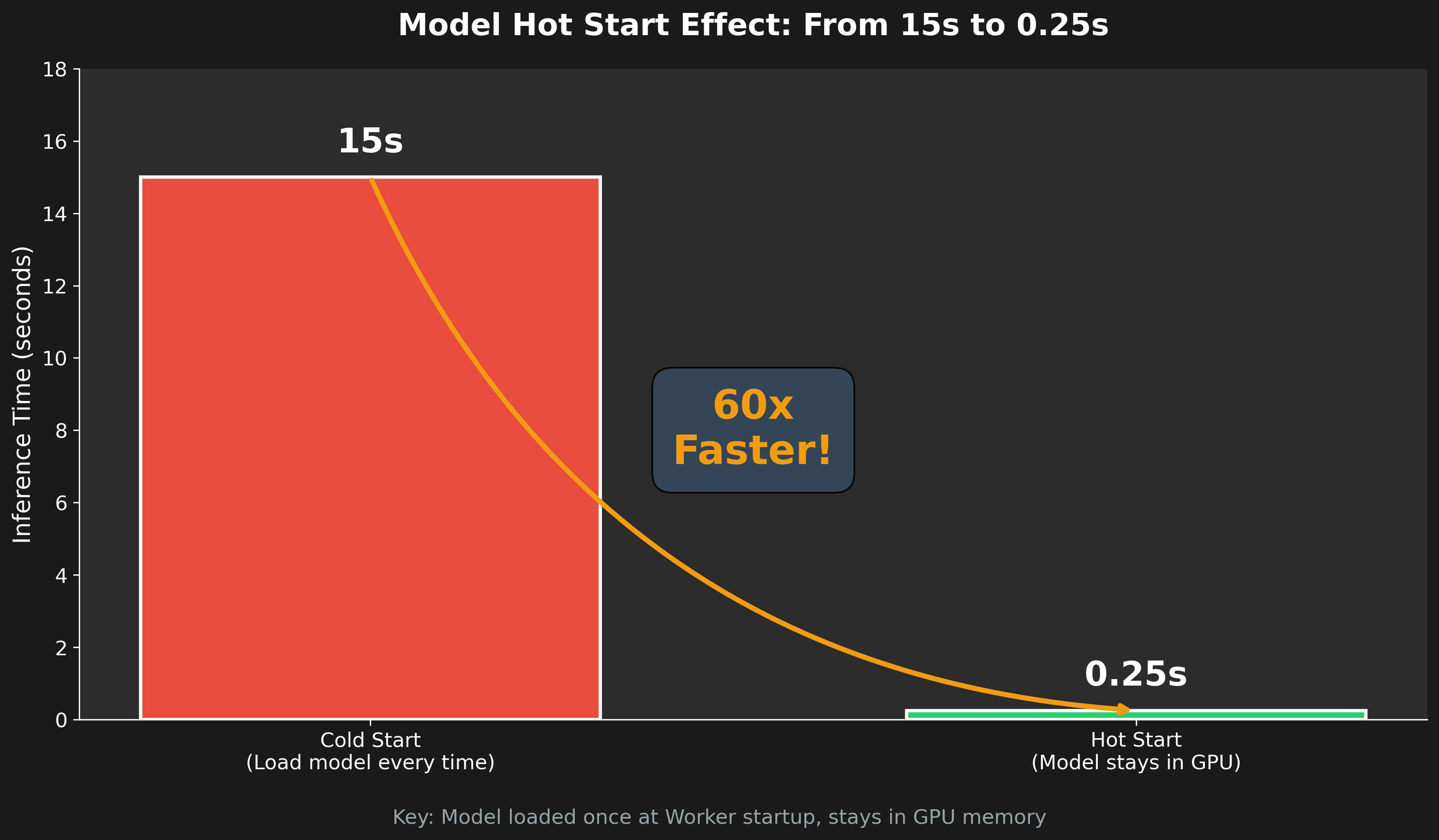
Cold Start (15s) vs Hot Start (0.25s),60 倍加速。
執行指南
Docker 環境
# 1. 啟動容器
docker-compose up -d
# 2. 進入容器
docker exec -it geo_decision_matrix bash
# 3. 啟動微服務
./run_microservices.sh
# 4. 測試 GPU 推論
./test_gpu_inference.sh
本地環境
# 1. 安裝依賴
pip install -r requirements.txt
# 2. 啟動服務
./run_microservices.sh
# 3. 測試
./test_gpu_inference.sh
下篇預告:3.4 效能陷阱篇
在發布 3.2 後,收到資深 Data Engineer 前輩的回饋:
「用 Python UDF 如果沒解釋原因,直接扣分。」
原來我在 Spark ETL 中使用的 Haversine UDF 寫法,是面試的經典地雷。
問題:Python UDF 會導致 JVM ↔ Python 之間頻繁序列化,是效能殺手。
下一篇將分享:
為什麼 Python UDF 是效能殺手?(Serialization Overhead)
如何用 Spark Native Functions 重構?
500 萬筆資料的 Benchmark 對比
面試防禦話術
敬請期待!
關鍵字:
系列文章:
3.3 算力解放篇:微服務 + 0.25 秒推論(本篇)
3.4 效能陷阱篇:UDF 重構 + 500 萬筆壓測(下篇)