Enterprise AI Gateway requires four architectural principles done together: Control by Configuration, Security by Architecture, Accountability by Default, Portability by Design. Miss one, and the gateway becomes an attack-surface amplifier.
The real bottleneck for AI agent adoption isn't tech — it's trust. CIOs aren't worried about model power; they have three unanswered questions: who commanded it, who's accountable, and where the data goes.
'Coding has no cost' is the wrong question. AI is not zeroing out engineering value — it is pushing responsibility up the stack. The real question is how companies and engineers adapt to that shift.
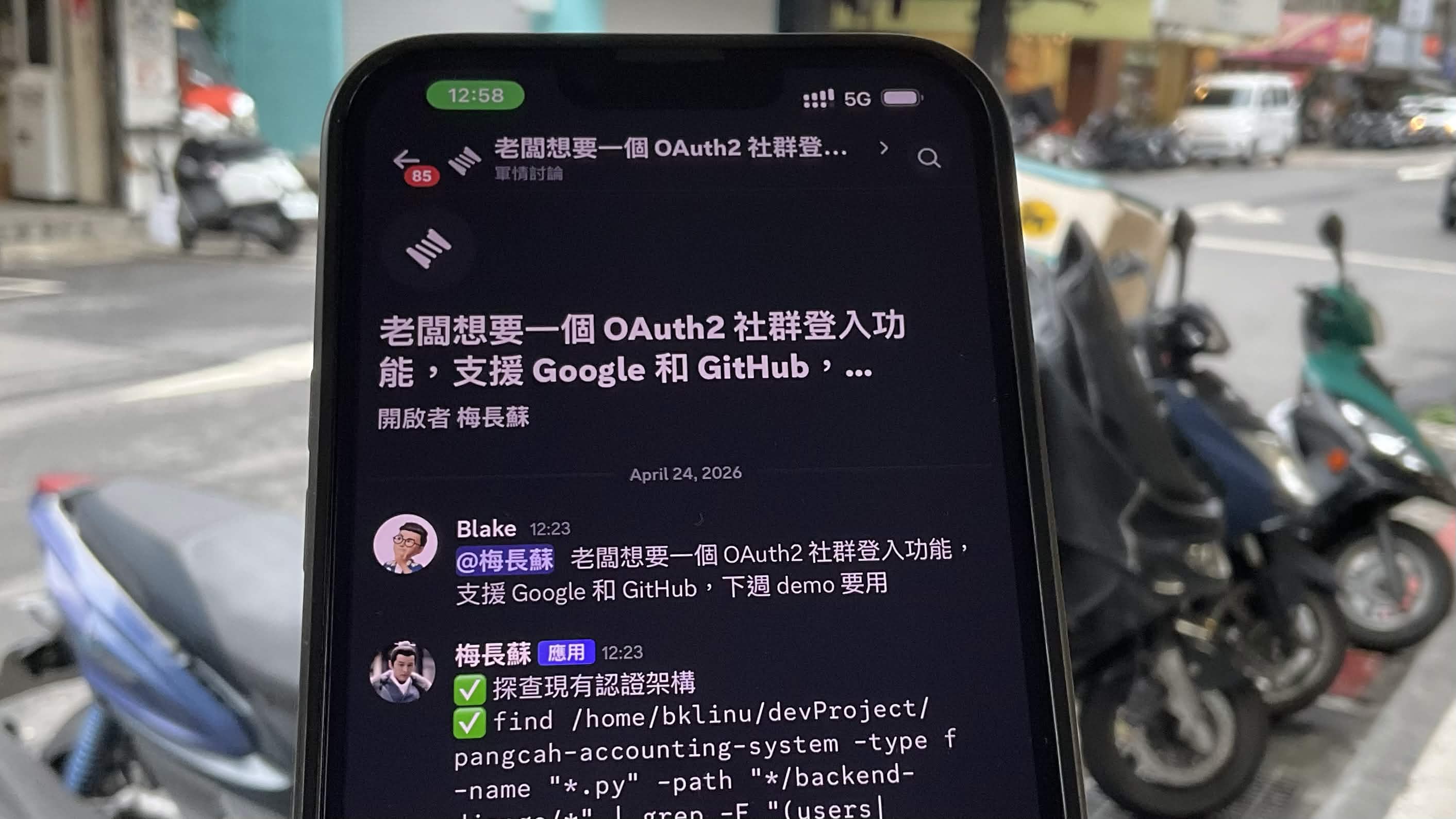
What chatbot builders figured out in 2016 — routing — the AI agent world forgot in 2026. The most popular AI tool throws everything at one AI. I use chatbot-era routing logic with an Attack on Titan squad formation: 5 AI agents on OpenAB, $120/month, 24/7. Kiro is free and handles 80% of dev. Claude only for architecture. It's not about having the strongest AI — get the routing right, and a free tool can be your workhorse.
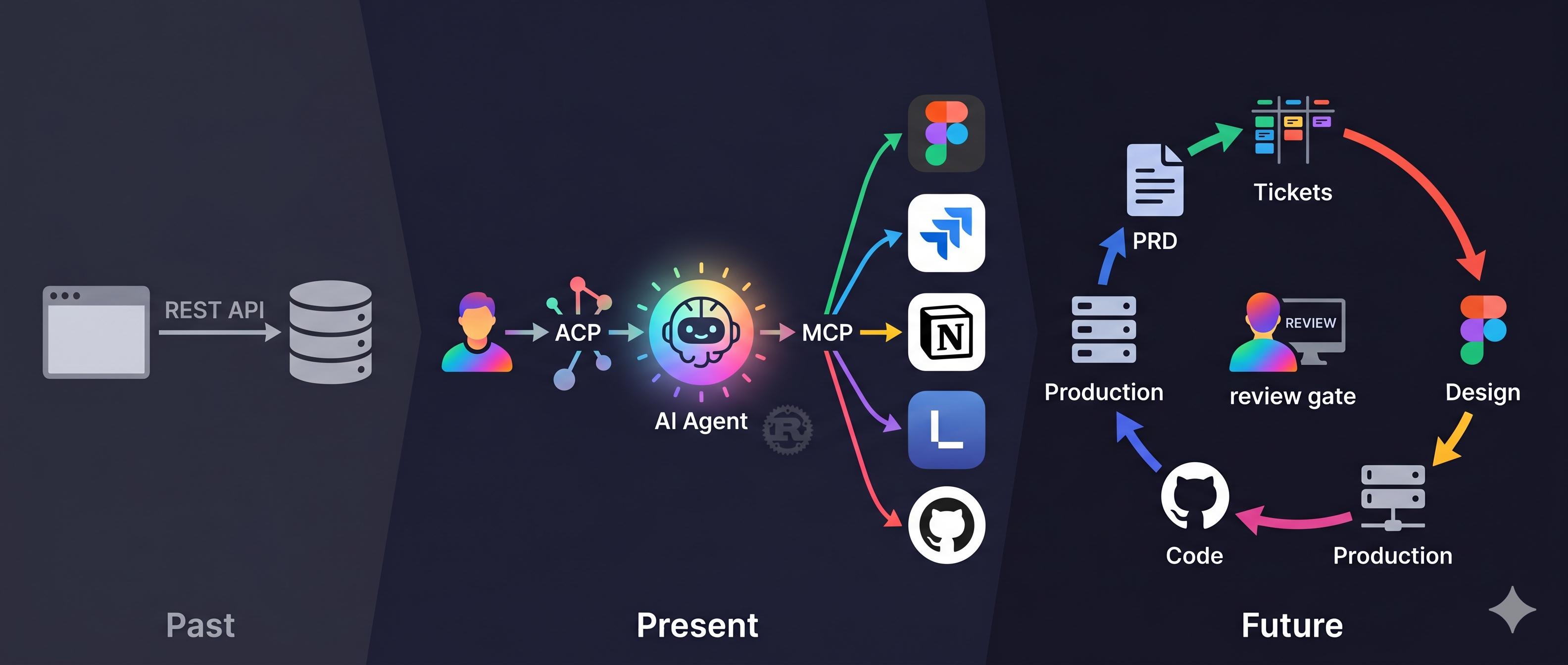
From rejecting OpenClaw to automating design handoff with OpenAB + Figma MCP + Jira MCP. Last week Anthropic suspended 60+ accounts overnight — validating why vendor-agnostic architecture matters. Covers technical trade-offs, cloud vs local AI, MCP × ACP as the enterprise AI battleground, and the no-human-code product architecture vision.
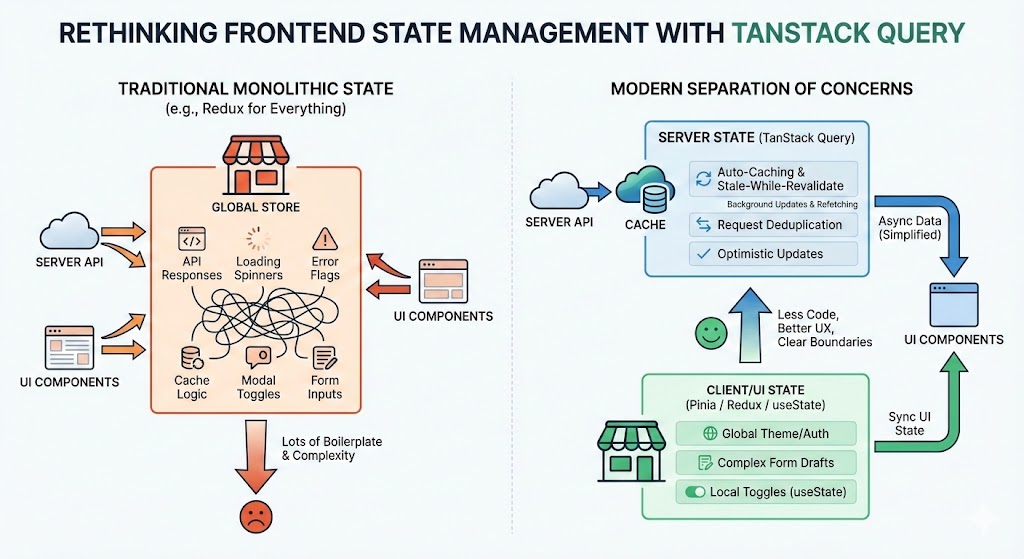
Most engineers use AI as a chatbot. This is what happens when you treat it as infrastructure — with the same rigor you'd apply to choosing a database or designing a deployment pipeline.
A practical guide to frontend testing using real production components — newsletter anti-spam validation, clap button debounce, and Markdown detection — with Vitest, React Testing Library, and Playwright.
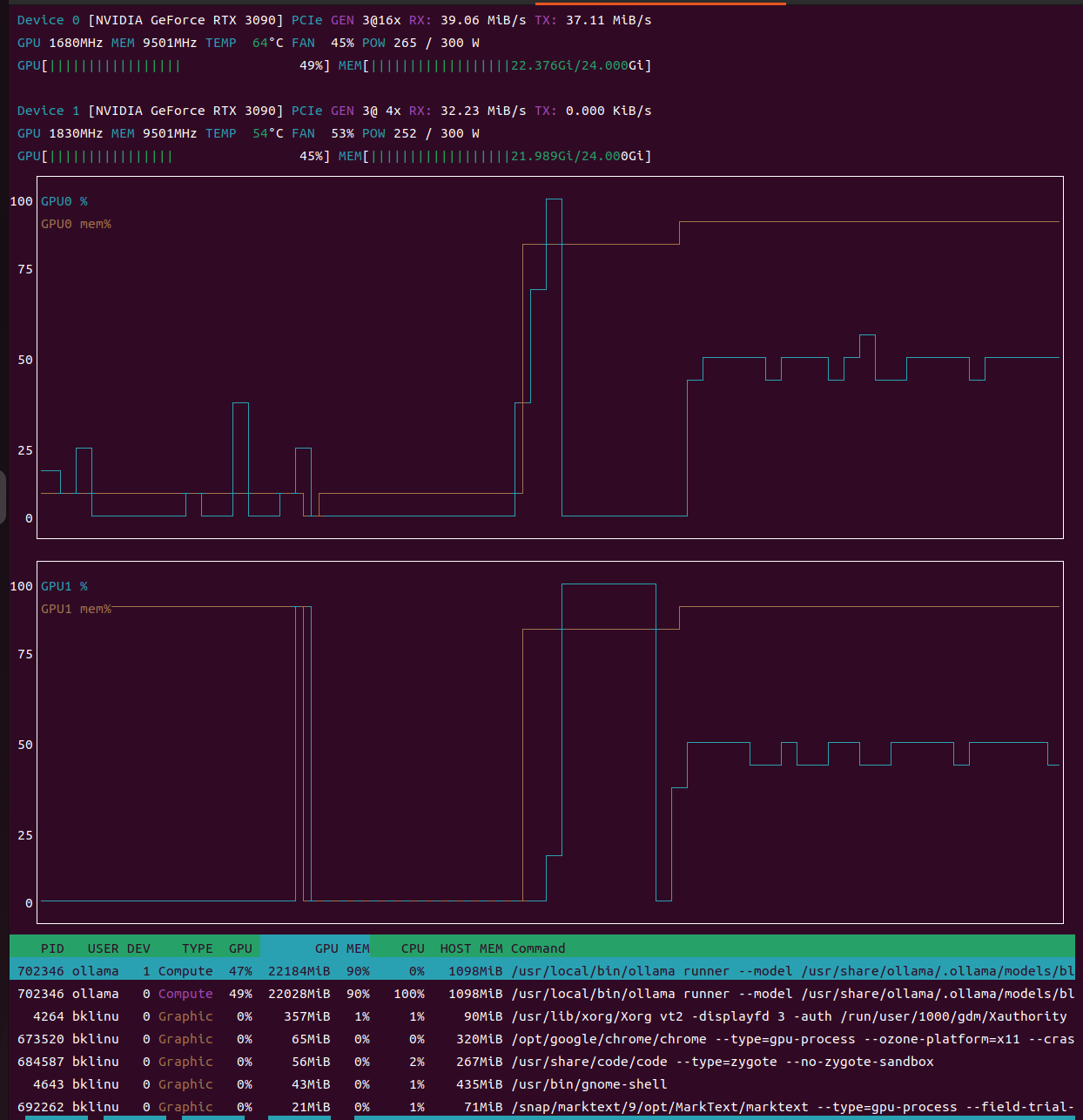
550 days working at the intersection of hardware and software — from building a unified control platform integrating 15+ PC hardware devices, to transitioning into full-stack development with Django + PostgreSQL, to architecting a Data Lakehouse POC with Apache Iceberg and Trino on my home lab. This is a technical retrospective on architecture evolution, backend engineering growth, and the path from frontend specialist to data engineering practitioner.
This article isn't about future chips. It is a record of how, in early 2026, I attempted to realize "full-scale data analysis" in a local environment. It’s the story of how I transformed a spare machine originally built for Windows client testing—using a power drill, an external power supply, and cables from Taobao—into a machine that crashed into a physical wall, only to be reborn.
#
Home Lab #
Edge AI #
Hardware Modding #
RTX 3090
+5
This article explains how a migration from Node.js to PySpark surfaced an unexpected bottleneck: LLMs were failing with “Context Window Exceeded” not because CSV files were large in megabytes, but because high‑precision GPS floats created extremely dense tokens. By showing how a value like 121.5654321 is split into multiple tokens, while a truncated 121.56 uses fewer, it reframes precision itself as a cost driver in token‑bounded systems. The proposed fix is a precision truncation layer in the ETL pipeline that rounds floats to domain‑appropriate precision (for GPS, typically 2 decimals), which reduces input tokens per coordinate by about 25% and increases the number of rows that fit into a fixed context window by roughly one‑third.
#
Claude API #
Context Engineering #
AI Performance Engineering #
Cost Optimization
+11
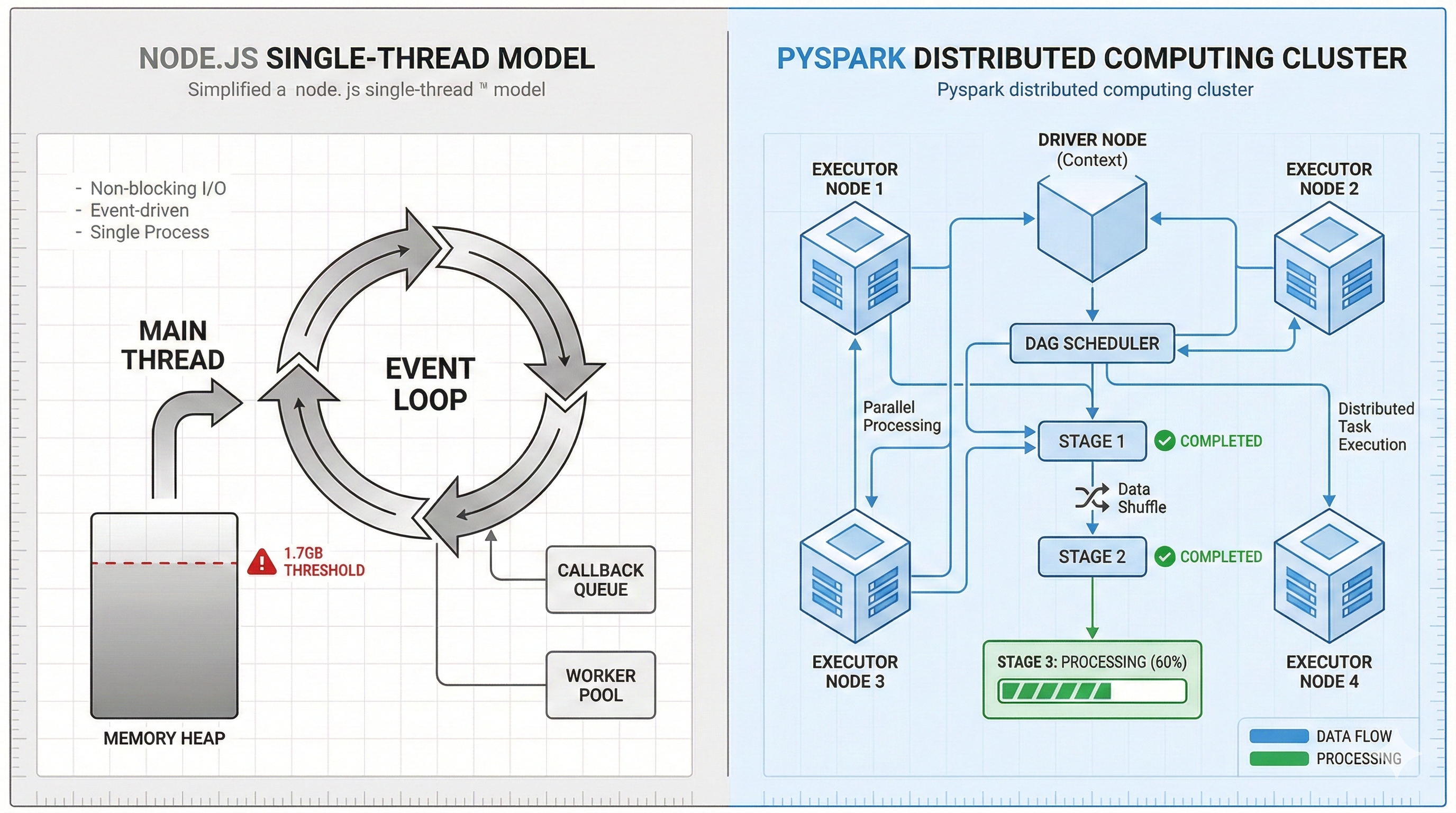
When processing 500,000 map trajectory records, the Node.js single-threaded architecture crashed after 3.2 seconds due to memory overflow (1.7GB), while the PySpark distributed architecture stably completed the full dataset processing (19.88 seconds). This article presents a controlled experiment comparing the performance differences between these two architectures in large-scale data processing, exploring the physical limits of the Event Loop, Spark's DAG execution mechanism, and defensive strategies against floating-point precision issues. The experimental data suggests that system stability often has more practical value than peak performance when processing large datasets.
This article tells the story of an engineer who tried to cut 30% of mapping API costs, but due to survivorship bias and sample-based testing, nearly crashed a SaaS food-delivery order system within 15 minutes of launch.
A pre-built Feature Flag became the only escape hatch, enabling an instant rollback to Google Maps and stopping mounting compensation risks in under 45 minutes.
Three years later, the same engineer revisits the incident using Apache Spark, real-time data pipelines, and LLMs to build an intelligent decision matrix, evolving from a Senior who could only triage incidents into an Architect who designs systems to proactively manage business risk.
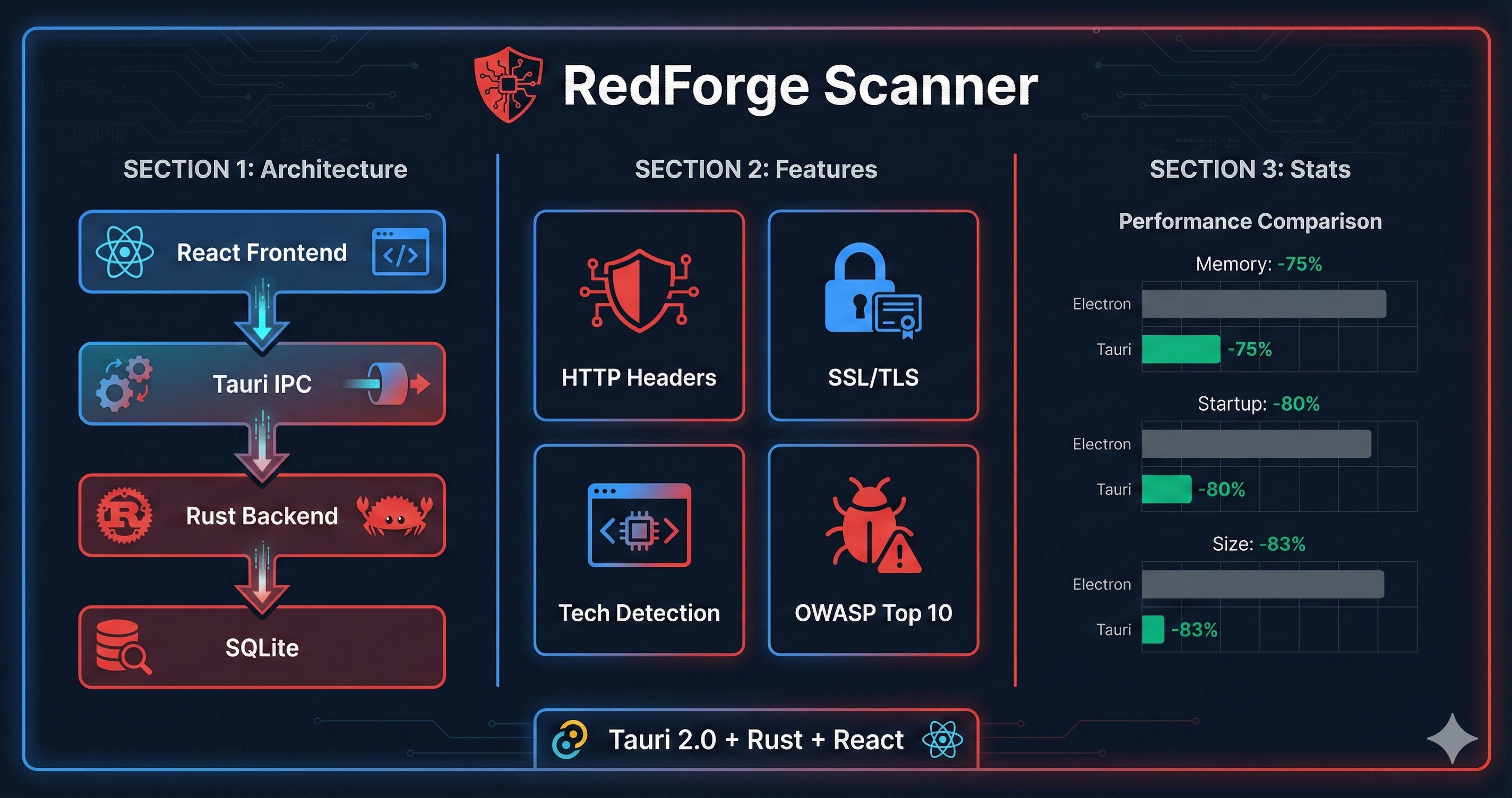
This article shares a lightweight observability implementation designed specifically for PC hardware control software (RGB, fan control, etc.). By using "Exceptions + Structured Logs" instead of full TEMPLE, in 6 months of production use, problem diagnosis time dropped from 10-14 days to 1-2 days, with average engineering hours reduced ~80%, and some cases achieving 83-85% efficiency improvement. Key highlights include: Four-layer log classification (DEVICE/AUTH/APP/SYSTEM), 5W1H structured fields for hardware operations, IPC logging pipeline in Electron + Native Add-on architecture, and async batching with intelligent throttling keeping additional latency to 1-2ms, balancing observability with performance.
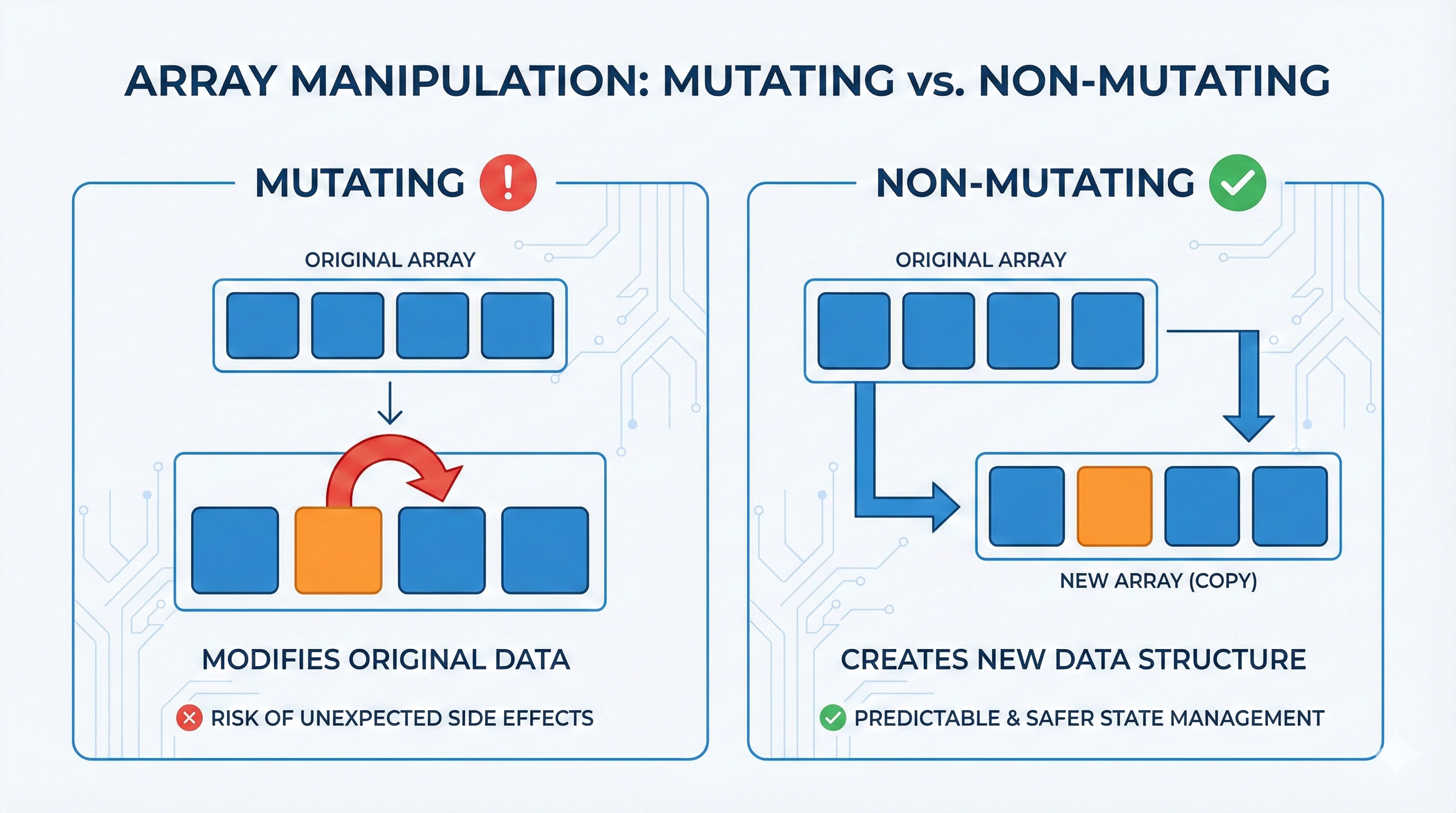
Understanding React's rendering mechanism is critical for writing efficient applications. This article systematically analyzes the execution timing of useEffect and useLayoutEffect, their appropriate use cases, and React 18's new batching mechanism. Mastering these concepts will help you avoid common performance issues and UI flickering.
As Blake Lab's cultural-technology integration experiment, Day 5 dives deep into product management practice, exploring how to balance the dual roles of engineer and product manager in solo development, driving PAPA system iteration optimization through user feedback.
As Blake Lab's cultural-technology integration experiment, Day 4 dives into Tauri desktop development, showing how to create native desktop experiences for macOS and Windows using web technologies, with large-screen friendly interfaces designed specifically for elders.
PAPA 是專為阿美族家族設計的財務管理工具,透過7天開發實踐文化敏感設計方法論,將文化洞察轉化為具體功能:透明分帳機制尊重集體決策、大字體介面解決跨世代鴻溝、彈性規則體現互助傳統。12位測試者(28-75歲)驗證成果顯著:長輩獨立操作成功率達80%、爭議減少50%、滿意度4.6/5。文章聚焦三階段方法(傾聽→轉化→驗證),提供可複製的原住民數位工具設計框架。





















![PAPA Development Journal [Day 5/7] - Product Management in Practice: Balancing Engineer and PM Dual Roles](https://res.cloudinary.com/dfaittd9e/image/upload/v1756694294/ChatGPT_Image_Sep_1_2025_10_32_22_AM_si2tlk.png)
![PAPA Development Journal [Day 4/7] - Tauri Desktop Edition: Cross-Platform Native Experience](https://res.cloudinary.com/dfaittd9e/image/upload/v1756439420/ChatGPT_Image_Aug_29_2025_11_50_07_AM_l77ikm.png)
![PAPA Development Journal [Day 3/7] - Django Backend Architecture & Smart Split Algorithms](https://res.cloudinary.com/dfaittd9e/image/upload/v1756352037/ChatGPT_Image_Aug_28_2025_11_33_16_AM_egphfr.png)
![PAPA Development Journal [Day 2/7] - Cultural-Sensitive UX Design for Four-Tier Permission Systems](https://res.cloudinary.com/dfaittd9e/image/upload/v1756261827/ChatGPT_Image_Aug_27_2025_10_30_11_AM_maor9s.png)
![PAPA Development Log [Day 1/7] - From Tribal Needs to Product Definition](https://res.cloudinary.com/dfaittd9e/image/upload/v1756966376/ChatGPT_Image_Sep_4_2025_02_12_43_PM_mfhjcd.png)
![PAPA開發實錄 [Day 7/7] - 文化敏感設計的跨世代實踐](https://res.cloudinary.com/dfaittd9e/image/upload/v1756868527/ChatGPT_Image_Sep_3_2025_10_22_15_AM_luz3e6.png)
![PAPA開發實錄 [Day 6/7] - 效能優化與監控實戰](https://res.cloudinary.com/dfaittd9e/image/upload/v1756784167/ChatGPT_Image_Sep_2_2025_11_35_39_AM_es9tcz.png)
![PAPA開發實錄 [Day 1/7] - 從部落需求到產品定義](https://res.cloudinary.com/dfaittd9e/image/upload/v1756106260/ChatGPT_Image_Aug_25_2025_02_51_18_PM_znvf8g.png)